How we built a serverless SQL database
原文 https://www.cockroachlabs.com/blog/how-we-built-cockroachdb-serverless/
We recently announced general availability (GA) for Serverless, with support for change data capture (CDC), backup and restore, and a 99.99% uptime SLA. Read on to learn how CockroachDB Serverless works from the inside out, and why we can give it away for free – not free for some limited period, but free. It required some significant and fascinating engineering to get us there. I think you’ll enjoy reading about it in this blog or watching the recent presentation I gave with my colleague Emily Horing:
我们最近宣布了无服务器的全面可用性 (GA),支持变更数据捕获 (CDC)、备份和恢复以及 99.99% 的正常运行时间 SLA。 请继续阅读,了解 CockroachDB Serverless 从内到外的工作原理,以及为什么我们可以免费赠送它——不是在有限的时间内免费,而是免费。 我们需要一些重要且令人着迷的工程才能实现这一目标。 我想您会喜欢在这个博客中阅读相关内容或观看我最近与同事 Emily Horing 进行的演示:
What is CockroachDB Serverless?
If you’ve created a database before, you probably had to estimate the size and number of servers to use based on the expected traffic. If you guessed too low, your database would fall over under load and cause an outage. If you guessed too high or if your traffic came in bursts, you’d waste money on servers that are just sitting idle. Could there be a better way?
如果您之前创建过数据库,则可能必须根据预期流量估计要使用的服务器的大小和数量。 如果您猜测得太低,您的数据库将在负载下崩溃并导致中断。 如果您猜测过高或者流量突然增加,您就会在闲置的服务器上浪费金钱。 还能有更好的办法吗?
Serverless means you don’t have to think about servers. Of course there are servers hard at work handling your application’s requests, but that’s our problem, not yours. We do all the hard work behind the scenes of allocating, configuring, and maintaining the servers. Instead of paying for servers, you pay for the requests that your application makes to the database and the storage that your data consumes.
无服务器意味着您不必考虑服务器。 当然,有些服务器正在努力处理您的应用程序的请求,但这是我们的问题,而不是您的问题。 我们在幕后完成分配、配置和维护服务器的所有艰苦工作。 您无需为服务器付费,而是为应用程序向数据库发出的请求以及数据消耗的存储付费。
You pay only for what you actually use, without needing to figure out up-front what that might be. If you use more, then we’ll automatically allocate more hardware to handle the increased load. If you use less, then you’ll pay less, or even nothing at all. And you’ll never be surprised by a bill, because you can set a guaranteed monthly resource limit. We’ll alert you as you approach that limit and give you options for how to respond.
您只需为实际使用的内容付费,无需预先弄清楚可能是什么。 如果您使用更多,那么我们将自动分配更多硬件来处理增加的负载。 如果你使用得少,那么你支付的费用就会少一些,甚至根本不需要支付任何费用。 而且您永远不会对账单感到惊讶,因为您可以设置有保证的每月资源限制。 当您接近该限制时,我们会提醒您,并为您提供如何应对的选项。
With just a few clicks or an API call, you can create a fully-featured CockroachDB database in seconds. You get an “always on” database that survives data center failure and keeps multiple encrypted copies of your data so you don’t lose it to hackers or hardware failure. It automatically and transparently scales to meet your needs, no matter how big or small, with no changes to your application. It supports online schema migrations, Postgres compatibility, and gives you unrestricted access to Enterprise features.
只需点击几下或 API 调用,您就可以在几秒钟内创建功能齐全的 CockroachDB 数据库。 您将获得一个“始终在线”的数据库,该数据库可以在数据中心发生故障时幸存下来,并保留数据的多个加密副本,这样您就不会因黑客或硬件故障而丢失数据。 它会自动、透明地扩展以满足您的需求,无论大小,而无需更改您的应用程序。 它支持在线架构迁移、Postgres 兼容性,并让您可以不受限制地访问企业功能。
Oh, and please use your favorite language, SDK, or tooling in whatever application environment you choose; using CockroachDB Serverless does not mean you have to use a Serverless compute service like AWS Lambda or Google Cloud Functions (though, that’s a great tool too!).
哦,请在您选择的任何应用程序环境中使用您最喜欢的语言、SDK 或工具; 使用 CockroachDB Serverless 并不意味着您必须使用 AWS Lambda 或 Google Cloud Functions 等无服务器计算服务(不过,这也是一个很棒的工具!)。
How can we afford to give this away? Well, certainly we’re hoping that some of you will build successful apps that “go big” and you’ll become paying customers. But beyond that, we’ve created an innovative Serverless architecture that allows us to securely host thousands of virtualized CockroachDB database clusters on a single underlying physical CockroachDB database cluster. This means that a tiny database with a few kilobytes of storage and a handful of requests costs us almost nothing to run, because it’s running on just a small slice of the physical hardware. I’ll explain how all this works in more detail below, but here’s a diagram to get you thinking:
我们怎么能承担得起放弃这个呢? 好吧,我们当然希望你们中的一些人能够构建成功的应用程序,“变大”,并且你们将成为付费客户。 但除此之外,我们还创建了一个创新的无服务器架构,使我们能够在单个底层物理 CockroachDB 数据库集群上安全地托管数千个虚拟化 CockroachDB 数据库集群。 这意味着一个具有几千字节存储空间和少量请求的小型数据库几乎不需要我们运行任何成本,因为它只在一小部分物理硬件上运行。 我将在下面更详细地解释这一切是如何工作的,但这里有一个图表可以让您思考:
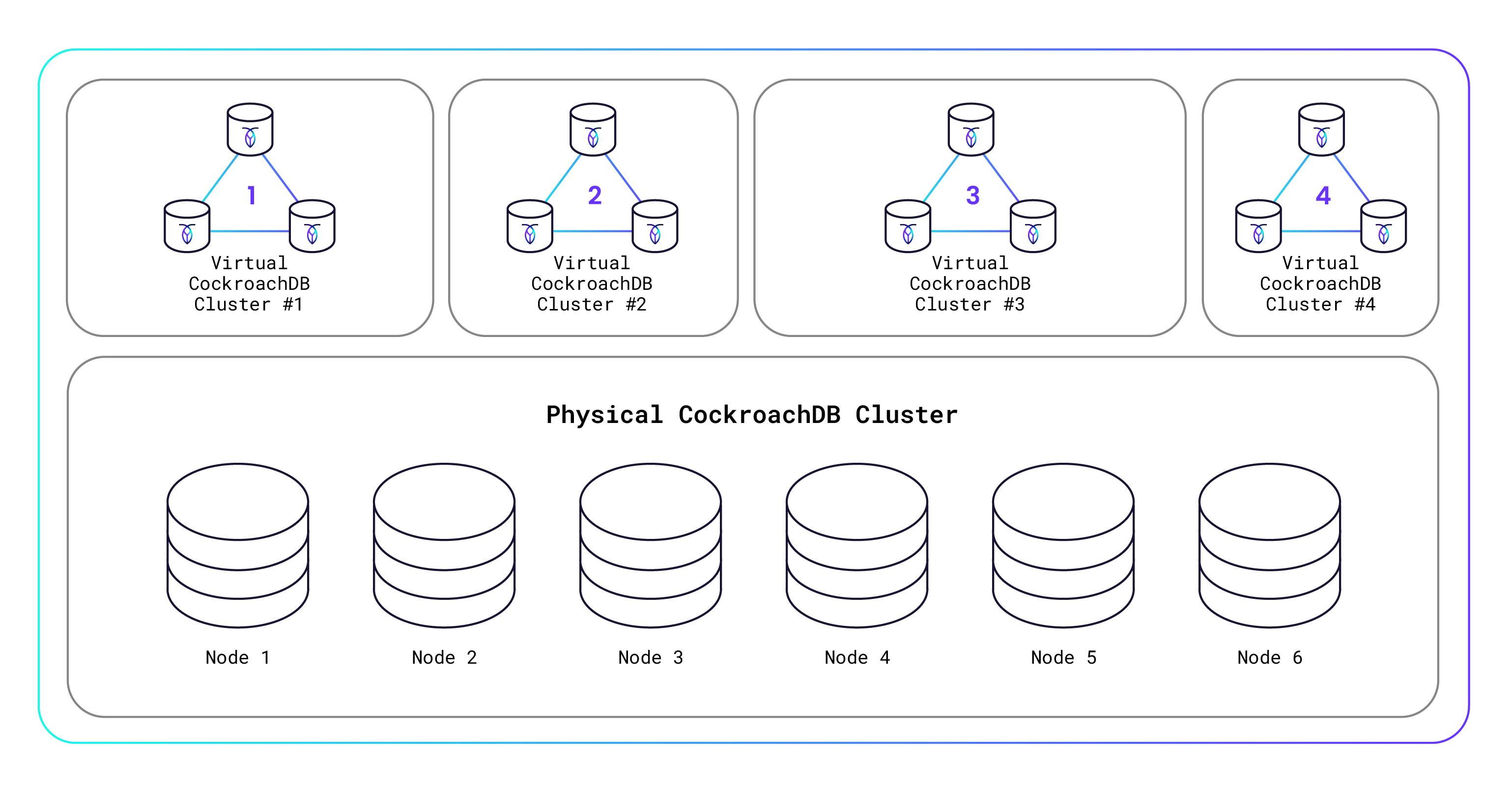
Single-Tenant Architecture
Before now, a single physical CockroachDB cluster was intended for dedicated use by a single user or organization. That is called single-tenancy. Over the past several CockroachDB releases, we’ve quietly been adding multi-tenancy support, which enables the physical CockroachDB cluster to be shared by multiple users or organizations (called “tenants”). Each tenant gets its own virtualized CockroachDB cluster that is hosted on the physical CockroachDB cluster and yet is secure and isolated from other tenants’ clusters. You’re probably familiar with how virtual machines (VMs) work, right? It’s kind of like that, only for database clusters.
在此之前,单个物理 CockroachDB 集群旨在供单个用户或组织专用。 这就是所谓的单租户。 在过去的几个 CockroachDB 版本中,我们一直在悄悄添加多租户支持,这使得物理 CockroachDB 集群能够由多个用户或组织(称为“租户”)共享。 每个租户都有自己的虚拟化 CockroachDB 集群,该集群托管在物理 CockroachDB 集群上,但安全且与其他租户的集群隔离。 您可能熟悉虚拟机 (VM) 的工作原理,对吧? 有点像那样,仅适用于数据库集群。
Before I can meaningfully explain how multi-tenancy works, I need to review the single-tenant architecture. To start with, a single-tenant CockroachDB cluster consists of an arbitrary number of nodes. Each node is used for both data storage and computation, and is typically hosted on its own machine. Within a single node, CockroachDB has a layered architecture. At the highest level is the SQL layer, which parses, optimizes, and executes SQL statements. It does this by a clever translation of higher-level SQL statements to simple read and write requests that are sent to the underlying key-value (KV) layer.
在我能够有意义地解释多租户如何工作之前,我需要回顾一下单租户架构。 首先,单租户 CockroachDB 集群由任意数量的节点组成。 每个节点都用于数据存储和计算,并且通常托管在自己的机器上。 在单个节点内,CockroachDB 具有分层架构。 最高层是SQL层,它解析、优化和执行SQL语句。 它通过巧妙地将高级 SQL 语句转换为发送到底层键值 (KV) 层的简单读写请求来实现此目的。
The KV layer maintains a transactional, distributed, replicated key-value store. That’s a mouthful, so let me break it down. Each key is a unique string that maps to an arbitrary value, like in a dictionary. KV stores these key-value pairs in sorted order for fast lookup. Multiple key-value pairs are also grouped into ranges. Each range contains a contiguous, non-overlapping portion of the total key-value pairs, sorted by key. Ranges are distributed across the available nodes and are also replicated at least three times, for high-availability. Key-value pairs can be added, removed, and updated in all-or-nothing transactions. Here is a simplified example of how a higher-level SQL statement gets translated into a simple KV GET call:
KV 层维护一个事务性、分布式、复制的键值存储。 这实在是太拗口了,所以让我来分解一下。 每个键都是一个唯一的字符串,映射到任意值,就像在字典中一样。 KV 按排序顺序存储这些键值对,以便快速查找。 多个键值对也被分组到范围中。 每个范围包含总键值对的连续、不重叠的部分,按键排序。 范围分布在可用节点上,并且至少复制三次,以实现高可用性。 可以在全有或全无事务中添加、删除和更新键值对。 下面是一个高级 SQL 语句如何转换为简单的 KV GET 调用的简化示例:
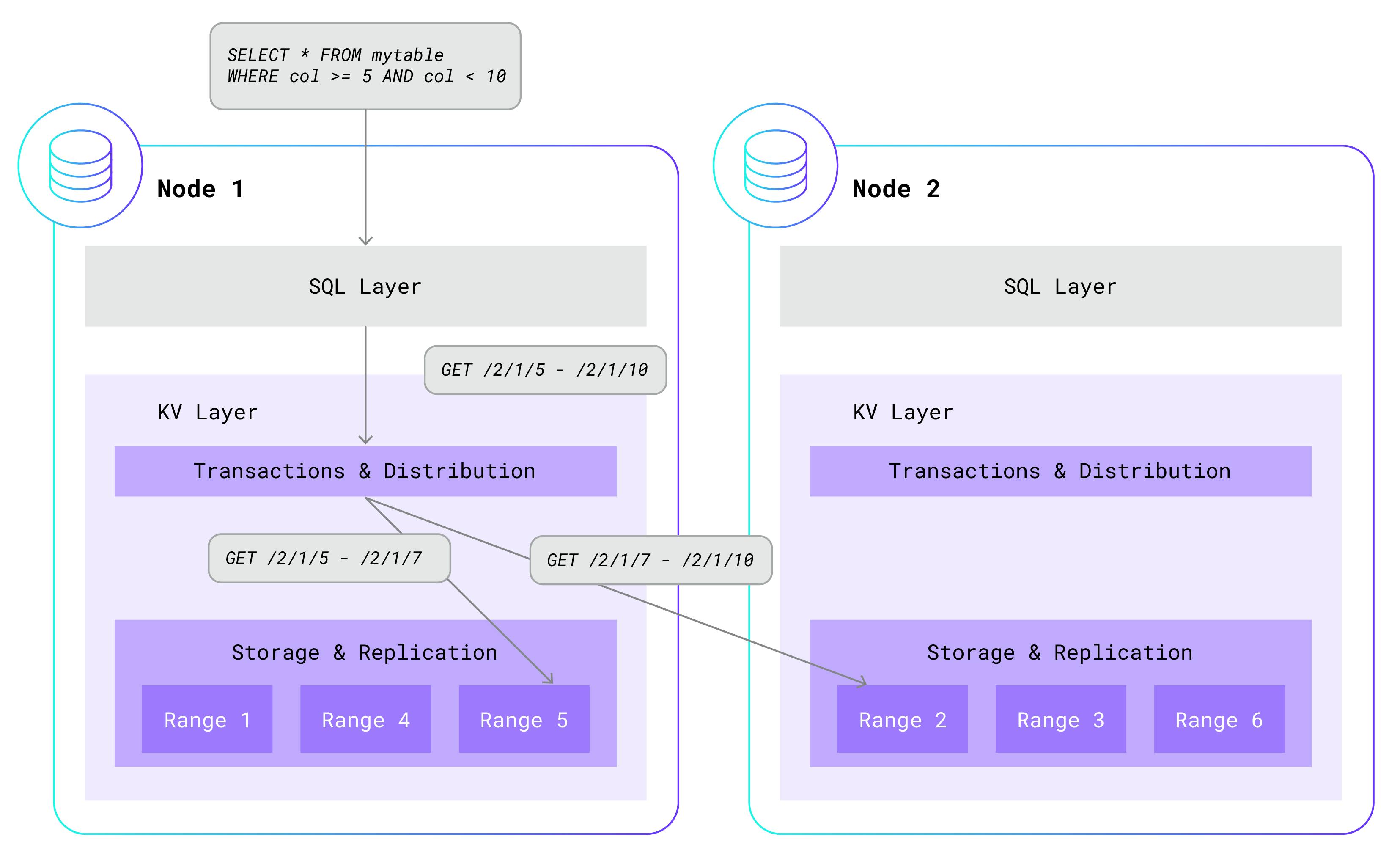
In single-tenant CockroachDB, the SQL layer is co-located with the KV layer on each node and in the same process. While the SQL layer always calls into the KV instance that runs on the same node, KV will often “fan-out” additional calls to other instances of KV running on other nodes. This is because the data needed by SQL is often located in ranges that are scattered across nodes in the cluster.
在单租户 CockroachDB 中,SQL 层与 KV 层位于每个节点上且位于同一进程中。 虽然 SQL 层总是调用在同一节点上运行的 KV 实例,但 KV 通常会“扇出”对在其他节点上运行的其他 KV 实例的额外调用。 这是因为 SQL 所需的数据通常位于分散在集群中节点的范围内。
Multi-Tenant Architecture
How do we extend that single-tenant architecture to support multiple tenants? Each tenant should feel like they have their own dedicated CockroachDB cluster, and should be isolated from other tenants in terms of performance and security. But that’s very difficult to achieve if we attempt to share the SQL layer across tenants. One tenant’s runaway SQL query could easily disrupt the performance of other tenants in the same process. In addition, sharing the same process would introduce many cross-tenant security threats that are difficult to reliably mitigate.
我们如何扩展单租户架构以支持多个租户? 每个租户都应该感觉自己拥有自己专用的 CockroachDB 集群,并且应该在性能和安全性方面与其他租户隔离。 但如果我们尝试跨租户共享 SQL 层,则很难实现这一点。 一个租户失控的 SQL 查询很容易破坏同一进程中其他租户的性能。 此外,共享同一进程会引入许多难以可靠缓解的跨租户安全威胁。
One possible solution to these problems would be to give each tenant its own set of isolated processes that run both the SQL and KV layers. However, that creates a different problem: we would be unable to share the key-value store across tenants. That eliminates one of the major benefits of a multi-tenant architecture: the ability to efficiently pack together the data of many tiny tenants in a shared storage layer.
解决这些问题的一个可能的解决方案是为每个租户提供一组自己的独立进程,这些进程同时运行 SQL 层和 KV 层。 然而,这会产生一个不同的问题:我们无法在租户之间共享键值存储。 这消除了多租户架构的主要优势之一:能够在共享存储层中有效地将许多小型租户的数据打包在一起。
After mulling over this problem, we realized that the dilemma can be elegantly solved by isolating some components and sharing other components. Given that the SQL layer is so difficult to share, we decided to isolate that in per-tenant processes, along with the transactional and distribution components from the KV layer. Meanwhile, the KV replication and storage components continue to run on storage nodes that are shared across all tenants. By making this separation, we get “the best of both worlds” – the security and isolation of per-tenant SQL processes and the efficiency of shared storage nodes. Here is an updated diagram showing two isolated per-tenant SQL nodes interacting with a shared storage layer:
经过思考这个问题,我们意识到可以通过隔离一些组件并共享其他组件来优雅地解决这个困境。 鉴于 SQL 层很难共享,我们决定将其与 KV 层的事务和分发组件一起隔离在每个租户进程中。 同时,KV 复制和存储组件继续在所有租户共享的存储节点上运行。 通过这种分离,我们获得了“两全其美”——每租户 SQL 进程的安全性和隔离性以及共享存储节点的效率。 下面是更新后的图表,显示了两个独立的每租户 SQL 节点与共享存储层交互:
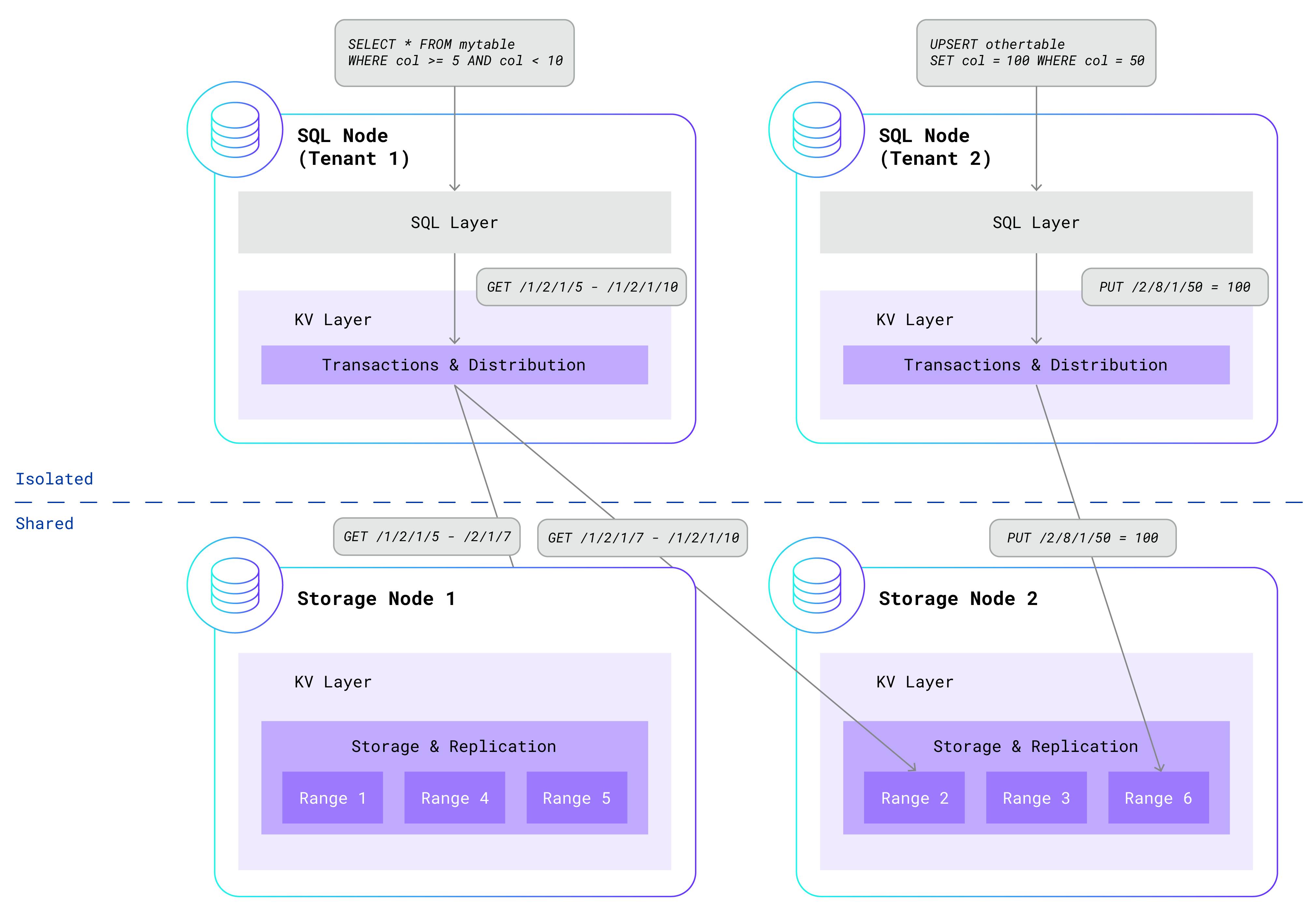
The storage nodes no longer run tenant SQL queries, but they still leverage the sophisticated infrastructure that powers single-tenant CockroachDB. Node failures are detected and repaired without impacting data availability. Leaseholders, which serve reads and coordinate writes for each range, move according to activity. Busy ranges are automatically split; quiet ranges are merged. Ranges are rebalanced across nodes based on load. The storage layer caches hot ranges in memory and pushes cold ones to disk. Three-way replication across availability zones ensures that your data is safely stored and highly available.
存储节点不再运行租户 SQL 查询,但它们仍然利用为单租户 CockroachDB 提供支持的复杂基础设施。 检测和修复节点故障不会影响数据可用性。 租用者负责为每个范围提供读取和协调写入服务,并根据活动进行移动。 繁忙范围自动分割; 安静范围被合并。 根据负载在节点之间重新平衡范围。 存储层将热范围缓存在内存中,并将冷范围推送到磁盘。 跨可用区的三向复制可确保您的数据安全存储且高度可用。
After seeing this architecture, you might be wondering about the security of the shared storage nodes. We spent significant time designing and implementing strong security measures to protect tenant data. Each tenant receives an isolated, protected portion of the KV keyspace. This is accomplished by prefixing every key generated by the SQL layer with the tenant’s unique identifier. Rather than generating a key like /<table-id>/<index-id>/<key>, SQL will generate a key like /<tenant-id>/<table-id>/<index-id>/<key>. This means that key-value pairs generated by different tenants are isolated in their own ranges. Furthermore, the storage nodes authenticate all communication from the SQL nodes and ensure that each tenant can only touch keys that are prefixed by its own tenant identifier.
看到这个架构后,您可能想知道共享存储节点的安全性。 我们花费了大量时间设计和实施强大的安全措施来保护租户数据。 每个租户都会收到 KV 键空间的一个隔离的、受保护的部分。 这是通过为 SQL 层生成的每个键添加租户的唯一标识符作为前缀来实现的。 SQL 不会生成像 /
Besides security, we were also concerned about ensuring basic quality of service across tenants. What happens if KV calls from multiple tenants threaten to overload a storage node? In that case, CockroachDB admission control kicks in. The admission control system integrates with the Go scheduler and maintains queues of work that ensure fairness across tenants. Each tenant’s GET, PUT, and DELETE requests are given a roughly equal allocation of CPU time and storage I/O. This ensures that a single tenant cannot monopolize resources on a storage node.
除了安全之外,我们还担心确保租户的基本服务质量。 如果来自多个租户的 KV 调用可能导致存储节点过载,会发生什么情况? 在这种情况下,CockroachDB 准入控制就会发挥作用。准入控制系统与 Go 调度程序集成并维护工作队列,以确保租户之间的公平性。 每个租户的 GET、PUT 和 DELETE 请求都会获得大致相等的 CPU 时间和存储 I/O 分配。 这样可以保证单个租户不能独占存储节点上的资源。
Serverless Architecture
Wait…wasn’t the last section about the Serverless architecture? Well, yes and no. As discussed, we’ve made significant upgrades to the core database architecture to support multi-tenancy. But that’s only half of the story. We also needed to make big enhancements in how we deploy and operate multi-tenant CockroachDB clusters in order to make Serverless possible.
等等……最后一节不是关于 Serverless 架构的吗? 嗯,是的,也不是。 正如所讨论的,我们对核心数据库架构进行了重大升级以支持多租户。 但这只是故事的一半。 我们还需要对多租户 CockroachDB 集群的部署和操作方式进行重大改进,以使无服务器成为可能。
Our managed cloud service uses Kubernetes (K8s) to operate Serverless clusters, including both shared storage nodes and per-tenant SQL nodes. Each node runs in its own K8s pod, which is not much more than a Docker container with a virtualized network and a bounded CPU and memory capacity. Dig down deeper, and you’ll discover a Linux cgroup that can reliably limit the CPU and memory consumption for the processes. This allows us to easily meter and limit SQL resource consumption on a per-tenant basis. It also minimizes interference between pods that are scheduled on the same machine, giving each tenant a high-quality experience even when other tenants are running heavy workloads.
我们的托管云服务使用 Kubernetes (K8s) 来操作无服务器集群,包括共享存储节点和每租户 SQL 节点。 每个节点都在自己的 K8s pod 中运行,该 pod 只不过是一个具有虚拟化网络以及有限的 CPU 和内存容量的 Docker 容器。 深入挖掘,您会发现 Linux cgroup 可以可靠地限制进程的 CPU 和内存消耗。 这使我们能够轻松地计量和限制每个租户的 SQL 资源消耗。 它还最大限度地减少了安排在同一台机器上的 Pod 之间的干扰,即使其他租户运行繁重的工作负载,也能为每个租户提供高质量的体验。
Here is a high-level (simplified) representation of what a typical setup looks like:
以下是典型设置的高级(简化)表示: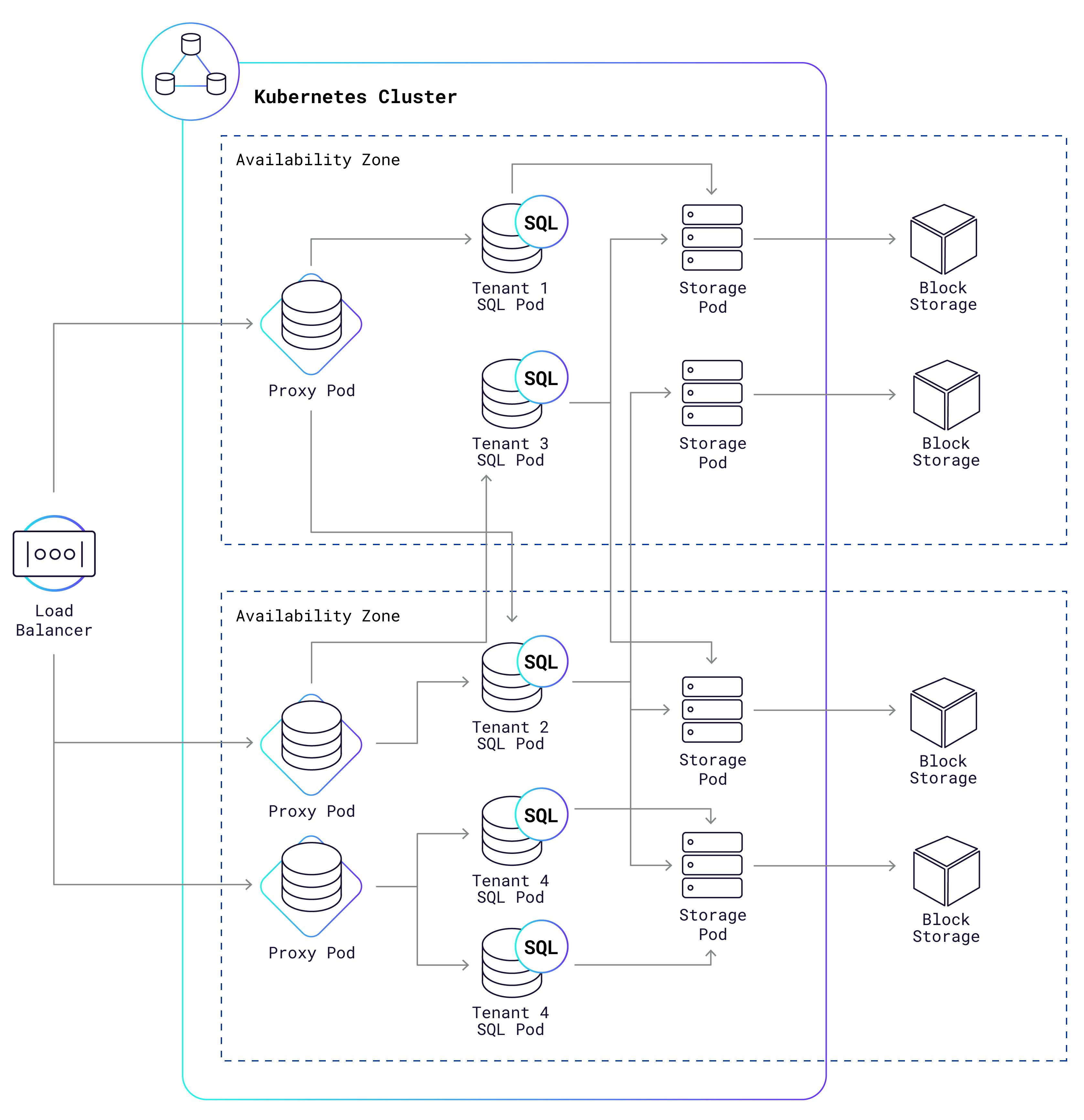
What are those “proxy pods” doing in the K8s cluster? It turns out they’re pretty useful:
这些“代理 Pod”在 K8s 集群中做什么? 事实证明它们非常有用:
They allow many tenants to share the same IP address. When a new connection arrives, the proxy “sniffs” the incoming Postgres connection packets in order to find the tenant identifier in a SNI header or aPG connection option. Now it knows which SQL pods it should route that connection to.
它们允许许多租户共享相同的 IP 地址。 当新连接到达时,代理“嗅探”传入的 Postgres 连接数据包,以便在 SNI 标头或 aPG 连接选项中查找租户标识符。 现在它知道应该将该连接路由到哪些 SQL Pod。
They balance load across a tenant’s available SQL pods, using a “least connections” algorithm.
它们使用“最少连接”算法来平衡租户可用 SQL Pod 之间的负载。
They detect and respond to suspected abuse of the service. This is one of the security measures we take for the protection of your data.
他们检测并响应可疑的服务滥用行为。 这是我们为保护您的数据而采取的安全措施之一。
They automatically resume tenant clusters that have been paused due to inactivity. We’ll get into more detail on that in the Scaling section below.
它们会自动恢复因不活动而暂停的租户集群。 我们将在下面的“缩放”部分中详细介绍这一点。
After the cloud load balancer routes a new connection to one of the proxy pods, the proxy pod will in turn forward that connection to a SQL pod owned by the connecting tenant. Each SQL pod is dedicated to just one tenant, and multiple SQL pods can be owned by the same tenant. Network security rules prevent SQL pods from talking to one another, unless they are owned by the same tenant. Finally, the SQL pods communicate via the KV layer to access data managed by the shared storage pods, each of which stores that data in a cloud provider block storage system like AWS EBS or GCP PD.
云负载均衡器将新连接路由到其中一个代理 Pod 后,代理 Pod 会将该连接转发到连接租户拥有的 SQL Pod。 每个 SQL Pod 仅专用于一个租户,同一租户可以拥有多个 SQL Pod。 网络安全规则阻止 SQL Pod 相互通信,除非它们属于同一租户。 最后,SQL Pod 通过 KV 层进行通信,以访问由共享存储 Pod 管理的数据,每个存储 Pod 都将该数据存储在 AWS EBS 或 GCP PD 等云提供商块存储系统中。
One of the best things about Serverless clusters is how fast they can be created. A regular Dedicated cluster takes 20-30 minutes to launch, since it has to create a cloud provider project, spin up new VMs, attach block storage devices, allocate IP and DNS addresses, and more. By contrast, a Serverless cluster takes just a few seconds to create, since we only need to instruct K8s to create a new SQL pod on an existing VM that it is already managing.
无服务器集群的优点之一是它们的创建速度有多快。 常规专用集群需要 20-30 分钟才能启动,因为它必须创建云提供商项目、启动新虚拟机、连接块存储设备、分配 IP 和 DNS 地址等。 相比之下,无服务器集群的创建只需要几秒钟,因为我们只需要指示 K8s 在它已经管理的现有虚拟机上创建一个新的 SQL Pod。
Besides speed of creation, Serverless SQL pods also have a big cost advantage. They can be packed together on a VM, sharing the same OS as well as available CPU and memory. This substantially reduces the cost of running “long-tail” tenants that have minuscule workloads, since they can each use just a small slice of the hardware. Contrast this with a dedicated VM, which generally requires at least 1 vCPU and 1GB of memory to be reserved for it.
除了创建速度之外,Serverless SQL Pod 还具有很大的成本优势。 它们可以打包在一个虚拟机上,共享相同的操作系统以及可用的 CPU 和内存。 这大大降低了运行工作负载极小的“长尾”租户的成本,因为他们每个人只能使用一小部分硬件。 与此相比,专用虚拟机通常需要为其保留至少 1 个 vCPU 和 1GB 内存。
Scaling
As the amount of data owned by a tenant grows, and the frequency with which that data is accessed grows, the tenant’s data will be split into a growing number of KV ranges which will be spread across more shared storage pods. Data scaling of this kind is already well supported by CockroachDB, and operates in about the same way in multi-tenant clusters as it always has in single-tenant clusters. I won’t cover that kind of scaling in any more detail here.
随着租户拥有的数据量的增加以及数据访问频率的增加,租户的数据将被分割成越来越多的 KV 范围,这些 KV 范围将分布在更多的共享存储 Pod 中。 CockroachDB 已经很好地支持了这种类型的数据扩展,并且在多租户集群中的运行方式与在单租户集群中的运行方式大致相同。 我不会在这里更详细地介绍这种缩放。
Similarly, as the number of SQL queries and transactions run against a tenant’s data increases, the compute resources allocated to that tenant must grow proportionally. One tenant’s workload may need dozens or even hundreds of vCPUs to execute, while another tenant’s workload may just need a part-time fraction of a vCPU. In fact, we expect most tenants to not need any CPU at all. This is because a large proportion of developers who try CockroachDB Serverless are just “kicking the tires”. They’ll create a cluster, maybe run a few queries against it, and then abandon it, possibly for good. Even keeping a fraction of a vCPU idling for their cluster would be a tremendous waste of resources when multiplied by all inactive clusters. And even for tenants who regularly use their cluster, SQL traffic load is not constant; it may greatly fluctuate from day to day and hour to hour, or even second to second.
同样,随着针对租户数据运行的 SQL 查询和事务数量增加,分配给该租户的计算资源也必须成比例增长。 一个租户的工作负载可能需要数十甚至数百个 vCPU 来执行,而另一个租户的工作负载可能只需要 vCPU 的兼职部分。 事实上,我们预计大多数租户根本不需要任何 CPU。 这是因为尝试 CockroachDB Serverless 的开发人员中有很大一部分只是“尝试一下”。 他们将创建一个集群,也许对其运行一些查询,然后放弃它,可能会永远放弃它。 当乘以所有不活动集群时,即使让集群的一小部分 vCPU 处于空闲状态,也会造成巨大的资源浪费。 即使对于经常使用集群的租户来说,SQL 流量负载也不是恒定的; 它可能每天、每小时、甚至每秒都有很大的波动。
How does CockroachDB Serverless handle such a wide range of shifting resource needs? By dynamically allocating the right number of SQL pods to each tenant, based on its second-to-second traffic load. New capacity can be assigned instantly in the best case and within seconds in the worst case. This allows even extreme spikes in tenant traffic to be handled smoothly and with low latency. Similarly, as traffic falls, any SQL pod that is no longer needed can be shut down, with any remaining SQL connections transparently migrated to other pods for that tenant. If traffic falls to zero and no SQL connections remain, then all SQL pods owned by the now inactive tenant are terminated. As soon as new traffic arrives, a new SQL pod can be spun back up within a few hundred milliseconds. This allows a seldom-used CockroachDB Serverless cluster to still offer production-grade latencies for almost no cost to Cockroach Labs, and no cost at all to the user.
CockroachDB Serverless 如何处理如此广泛的不断变化的资源需求? 根据每个租户的每秒流量负载,动态地为每个租户分配正确数量的 SQL Pod。 在最好的情况下可以立即分配新容量,在最坏的情况下可以在几秒钟内分配新容量。 这使得即使租户流量出现极端峰值也能以低延迟顺利处理。 同样,随着流量下降,任何不再需要的 SQL Pod 都可以关闭,任何剩余的 SQL 连接都会透明地迁移到该租户的其他 Pod。 如果流量降至零并且没有 SQL 连接剩余,则当前不活动租户拥有的所有 SQL Pod 将被终止。 一旦新流量到达,新的 SQL Pod 就可以在几百毫秒内恢复运行。 这使得很少使用的 CockroachDB Serverless 集群仍然可以提供生产级延迟,而 Cockroach Labs 几乎不需要任何成本,用户也不需要任何成本。
Such responsive scaling is only possible because multi-tenant CockroachDB splits the SQL layer from the KV storage layer. Because SQL pods are stateless, they can be created and destroyed at will, without impacting the consistency or durability of tenant data. There is no need for complex coordination between pods, or for careful commissioning and decommissioning of pods, as we must do with the stateful storage pods to ensure that all data stays consistent and available. Unlike storage pods, which typically remain running for extended periods of time, SQL pods are ephemeral and may be shut down within minutes of starting up.
这种响应式扩展之所以成为可能,是因为多租户 CockroachDB 将 SQL 层与 KV 存储层分开。 由于 SQL Pod 是无状态的,因此可以随意创建和销毁它们,而不会影响租户数据的一致性或持久性。 不需要在 Pod 之间进行复杂的协调,也不需要仔细调试和停用 Pod,而我们必须使用有状态存储 Pod 来确保所有数据保持一致和可用。 与通常长时间运行的存储 Pod 不同,SQL Pod 是短暂的,可能会在启动后几分钟内关闭。
The Autoscaler
Let’s dig a little deeper into the mechanics of scaling. Within every Serverless cluster, there is an autoscaler component that is responsible for determining the ideal number of SQL pods that should be assigned to each tenant, whether that be one, many, or zero. The autoscaler monitors the CPU load on every SQL pod in the cluster, and calculates the number of SQL pods based on two metrics:
让我们更深入地研究缩放机制。 在每个无服务器集群中,都有一个自动缩放器组件,负责确定应分配给每个租户的 SQL Pod 的理想数量,无论是 1 个、多个还是 0 个。 自动缩放器监视集群中每个 SQL Pod 上的 CPU 负载,并根据两个指标计算 SQL Pod 的数量:
- Average CPU usage over the last 5 minutes. 过去 5 分钟的平均 CPU 使用率。
- Peak CPU usage during the last 5 minutes. 过去 5 分钟内 CPU 使用率峰值。
Average CPU usage determines the “baseline” number of SQL pods that will be assigned to the tenant. The baseline deliberately over-provisions SQL pods so that there is spare CPU available in each pod for instant bursting. However, if peak CPU usage recently exceeded even the higher over-provisioned threshold, then the autoscaler accounts for that by increasing the number of SQL pods past the baseline. This algorithm combines the stability of a moving average with the responsiveness of an instantaneous maximum. The autoscaler avoids too-frequent scaling, but can still quickly detect and react to large spikes in load.
平均 CPU 使用率决定了将分配给租户的 SQL Pod 的“基准”数量。 该基线故意过度配置 SQL Pod,以便每个 Pod 中有可用的备用 CPU 进行即时爆发。 但是,如果峰值 CPU 使用率最近甚至超过了更高的超额配置阈值,则自动缩放程序会通过将 SQL Pod 数量增加到超过基线来解决这一问题。 该算法结合了移动平均值的稳定性和瞬时最大值的响应能力。 自动缩放器避免了过于频繁的缩放,但仍然可以快速检测负载的大峰值并做出反应。
Once the autoscaler has derived the ideal number of SQL pods, it triggers a K8s reconciliation process that adds or removes pods in order to reach the ideal number. The following diagram shows the possible outcomes:
一旦自动缩放器得出理想的 SQL Pod 数量,它就会触发 K8s 协调过程,添加或删除 Pod 以达到理想数量。 下图显示了可能的结果: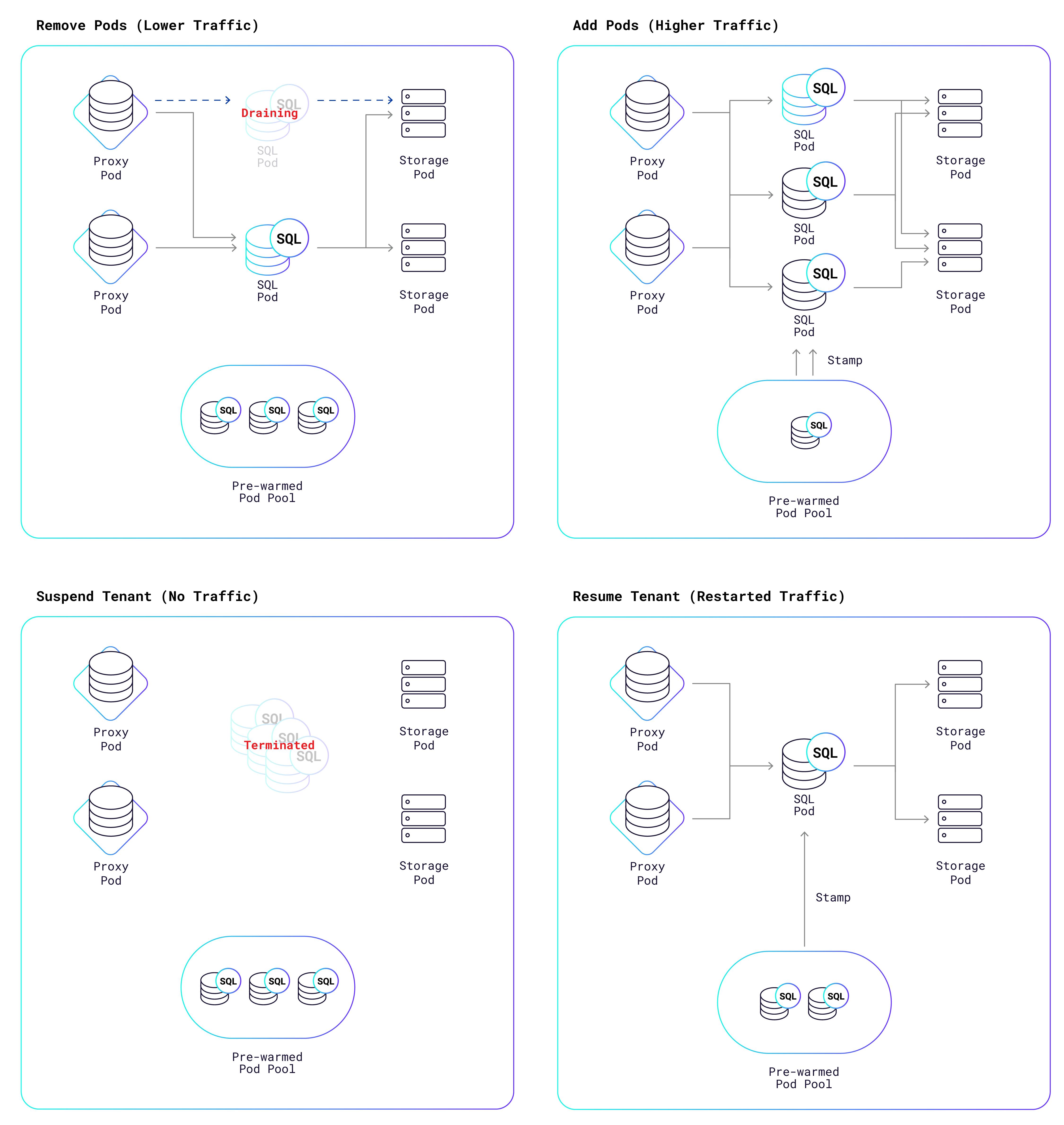
As the diagram shows, we maintain a pool of “prewarmed” pods that are ready to go at a moment’s notice; they just need to be “stamped” with the tenant’s identifier and security certificates. This takes a fraction of a second to do, versus the 20-30 seconds it takes for K8s to create a pod from scratch. If instead, pods need to be removed, they are not abruptly terminated, because that would also result in the rude termination of all SQL connections to that pod. Rather, the pods are put into a draining state, which gives them a chance to shed their SQL connections more gracefully. Some connections might be closed by the application; other connections will be transparently migrated by the proxy from the draining pods to other pods that are still active.A draining pod is terminated once all connections are gone or once 10 minutes have passed, whichever comes first.
如图所示,我们维护了一个“预热”的 Pod 池,随时可以启动; 他们只需要“盖上”租户的标识符和安全证书即可。 这只需几分之一秒的时间即可完成,而 K8s 从头开始创建 pod 需要 20-30 秒。 相反,如果需要删除 pod,它们不会突然终止,因为这也会导致粗暴终止与该 pod 的所有 SQL 连接。 相反,Pod 会进入耗尽状态,这使它们有机会更优雅地摆脱 SQL 连接。 某些连接可能会被应用程序关闭; 其他连接将由代理透明地从排出 Pod 迁移到其他仍处于活动状态的 Pod。一旦所有连接消失或经过 10 分钟(以先到者为准),排出 Pod 就会终止。
If application load falls to zero, then the autoscaler will eventually decide to suspend the tenant, which means that all of its SQL pods are removed. Once the tenant no longer owns any SQL pods, it does not consume any CPU, I/O, or bandwidth. The only cost is for storage of its data, which is relatively cheap compared to other resources. This is one of the reasons that we can offer free database clusters to all of you.
如果应用程序负载降至零,则自动缩放程序最终将决定暂停租户,这意味着其所有 SQL Pod 都将被删除。 一旦租户不再拥有任何 SQL Pod,它就不会消耗任何 CPU、I/O 或带宽。 唯一的成本是数据的存储,与其他资源相比相对便宜。 这是我们可以向大家提供免费数据库集群的原因之一。
However, there is one problem left to solve. How can a tenant connect to its cluster if there are no SQL pods assigned to it? To answer that question, remember that a set of proxy pods runs in every Serverless cluster. Each SQL connection initiated by an external client is intercepted by a proxy pod and then forwarded to a SQL pod assigned to the tenant. However, if the proxy finds that there are currently no SQL pods assigned to the tenant, then it triggers the same K8s reconciliation process that the autoscaler uses for scaling. A new pod is pulled from the prewarmed pool of SQL pods and stamped, and is now available for connections. The entire resumption process takes a fraction of a second, and we’re actively working on bringing that time down further.
然而,还有一个问题需要解决。 如果没有分配给租户的 SQL Pod,租户如何连接到其集群? 要回答这个问题,请记住每个无服务器集群中都运行一组代理 Pod。 外部客户端发起的每个 SQL 连接都会被代理 Pod 拦截,然后转发到分配给租户的 SQL Pod。 但是,如果代理发现当前没有分配给租户的 SQL Pod,则会触发自动缩放程序用于缩放的相同 K8s 协调过程。 从预热的 SQL Pod 池中提取一个新 Pod 并进行标记,现在可用于连接。 整个恢复过程只需要几分之一秒,我们正在积极努力进一步缩短这一时间。
Conclusion
Now that you know how CockroachDB Serverless works, I encourage you to head on over to https://cockroachlabs.cloud/ and give it a try. If you have questions about any of this, please join us in our Community Slack channel and ask away. We’d also love to hear about your experience with CockroachDB Serverless and any positive or negative feedback. We’ll be working hard to improve it over the coming months, so sign up for an account and get updates on our progress. And if you’d love to help us take CockroachDB to the next level, we’re hiring.
现在您已经了解了 CockroachDB Serverless 的工作原理,我鼓励您前往 https://cockroachlabs.cloud/ 并尝试一下。 如果您对此有任何疑问,请加入我们的 Community Slack 频道并提问。 我们也很想听听您使用 CockroachDB Serverless 的体验以及任何正面或负面的反馈。 我们将在未来几个月努力改进它,因此请注册一个帐户并获取有关我们进展的最新信息。 如果您愿意帮助我们将 CockroachDB 提升到一个新的水平,我们正在招聘。
Additional Resources
- Free online course: Introduction to Serverless Databases and CockroachDB Serverless. This course introduces the core concepts behind serverless databases and gives you the tools you need to get started with CockroachDB Serverless
- Bring us your feedback: Join our Slack community and let us know your thoughts!
- We’re hiring! Join the team building CockroachDB. Remote-friendly, family-friendly, and taking on some of the biggest challenges in data and app development.