How we built a cost-based SQL optimizer
Here at Cockroach Labs, we’ve had a continual focus on improving performance and scalability. To that end, our 2.1 release includes a brand-new, built-from-scratch, cost-based SQL optimizer. Besides enabling SQL features like correlated subqueries for the first time, it provides us with a flexible optimization framework that will yield significant performance improvements in upcoming releases, especially in more complex reporting queries. If you have queries that you think should be faster, send them our way! We’re building up libraries of queries that we use to tune the performance of the optimizer and prioritize future work.
在 Cockroach Labs,我们一直致力于提高性能和可扩展性。 为此,我们的 2.1 版本包含一个全新的、从头开始构建的、基于成本的 SQL 优化器。 除了首次启用相关子查询等 SQL 功能外,它还为我们提供了一个灵活的优化框架,该框架将在即将发布的版本中带来显着的性能改进,尤其是在更复杂的报告查询中。 如果您有任何您认为应该更快的查询,请发送给我们! 我们正在构建查询库,用于调整优化器的性能并确定未来工作的优先级。
While as an engineer, I’m eager to dive right into the details of how our new optimizer works (TL;DR - it’s very cool stuff), I need to first set the stage. I’ll start by explaining what a cost-based SQL optimizer is, and then tell you the story of how we decided we really, really needed one of those. Enough that we took 4 engineers, shut them into a windowless Slack room, and gave them carte blanche to rewrite a major component of CockroachDB. After story time, I’ll move onto the really interesting stuff, giving you a peek “under the hood” of the new optimizer. A peek will have to suffice, though, as digging deeper will require more words than one blog entry can provide. But do not despair; future articles will delve further into optimizer internals, so stay tuned.
作为一名工程师,我渴望深入了解我们的新优化器如何工作的细节(TL;DR - 这是非常酷的东西),我需要首先做好准备。 我将首先解释什么是基于成本的 SQL 优化器,然后告诉您我们如何决定我们真的非常需要其中一个的故事。 我们把 4 名工程师关在一个没有窗户的 Slack 房间里,全权让他们重写 CockroachDB 的一个主要组件。 故事时间结束后,我将转向真正有趣的内容,让您一睹新优化器的“幕后花絮”。 不过,浏览一下就足够了,因为深入挖掘需要的文字比一篇博客文章所能提供的还要多。 但不要绝望; 未来的文章将进一步深入探讨优化器的内部结构,敬请期待。
What is a SQL optimizer anyway?
A SQL optimizer analyzes a SQL query and chooses the most efficient way to execute it. While the simplest queries might have only one way to execute, more complex queries can have thousands, or even millions, of ways. The better the optimizer, the closer it gets to choosing the optimal execution plan, which is the most efficient way to execute a query.
SQL 优化器分析 SQL 查询并选择最有效的方法来执行它。 虽然最简单的查询可能只有一种执行方式,但更复杂的查询可能有数千甚至数百万种执行方式。 优化器越好,就越接近选择最佳执行计划,这是执行查询的最有效方式。
Here’s a query that looks deceptively simple:
这是一个看起来看似简单的查询:
1 | SELECT * |
I won’t bore you (or me) with the exhaustive list of questions that the optimizer must answer about this query, but here are a few to make my point:
我不会向您(或我)提供优化器必须回答的有关此查询的详尽问题列表,但这里有一些问题可以阐明我的观点:
Should we evaluate the name filter before the join or after the join?
我们应该在连接之前还是连接之后评估名称过滤器?
Should we use a hash join, merge join, or a nested loop join with an index (called a “lookup join” in CockroachDB)?
我们应该使用哈希连接、合并连接还是带有索引的嵌套循环连接(在 CockroachDB 中称为“查找连接”)?
If a lookup or hash join, should we enumerate customers and then lookup orders? Or enumerate orders and then lookup customers?
如果是查找或散列连接,我们是否应该枚举客户,然后查找订单? 或者枚举订单然后查找客户?
If there’s a secondary index on “name”, should we use that to find matching names, or is it better to use the primary index to find matching ids?
如果“name”上有二级索引,我们应该使用它来查找匹配的名称,还是使用主索引来查找匹配的 id 更好?
Furthermore, it’s not enough for the optimizer to answer each of these questions in isolation. To find the best plan, it needs to look at combinations of answers. Maybe it’s best to use the secondary index when choosing the lookup join. But, if a merge join is used instead, the primary index may be better. The optimal execution plan depends on row counts, relative performance of the various physical operators, the location and frequency of data values, and … a lot of other stuff.
此外,优化器单独回答这些问题是不够的。 为了找到最佳计划,需要考虑答案的组合。 也许在选择查找连接时最好使用二级索引。 但是,如果使用合并连接,主索引可能会更好。 最佳执行计划取决于行数、各种物理运算符的相对性能、数据值的位置和频率,以及……许多其他因素。
Heuristic vs. cost-based
So how do optimizers choose among so many possible execution plans? People have been thinking and writing about that longer than I’ve been alive, so any answer’s going to be inadequate. But, it’s still valuable to discuss two common approaches to the problem.
那么优化器如何在这么多可能的执行计划中进行选择呢? 人们思考和撰写这个问题的时间比我还活着的时间还要长,所以任何答案都是不够的。 但是,讨论解决该问题的两种常见方法仍然很有价值。
The first approach is what everyone who builds an optimizer for the first time takes. They come up with preset heuristic rules based on general principles. For example, there might be a heuristic rule to always use a hash join instead of a nested loop join if an equality condition is present. In most situations, that will result in a better execution plan, and so it’s a good heuristic. An optimizer based on rules like this is called a heuristic optimizer.
第一种方法是每个第一次构建优化器的人都会采用的方法。 他们根据一般原则提出预设的启发式规则。 例如,如果存在相等条件,则可能存在始终使用散列连接而不是嵌套循环连接的启发式规则。 在大多数情况下,这会产生更好的执行计划,因此这是一个很好的启发式方法。 基于此类规则的优化器称为启发式优化器。
However, static heuristic rules have a downside. They work well in most cases, but they can fail to find the best plan in other cases. For example, a lookup join loops over rows from an outer relation and looks for inner rows that match by repeatedly probing into an index over the inner relation. This works well when the number of outer rows is small, but degrades as that number rises and the overhead of probing for every row begins to dominate execution time. At some cross-over point, a hash or merge join would have been better. But it’s difficult to devise heuristics that capture these subtleties.
然而,静态启发式规则有一个缺点。 它们在大多数情况下工作良好,但在其他情况下可能无法找到最佳计划。 例如,查找连接循环遍历外部关系中的行,并通过重复探测内部关系上的索引来查找匹配的内部行。 当外部行数较少时,这种方法效果很好,但随着外部行数的增加,并且每行探测的开销开始主导执行时间,这种方法就会降低。 在某些交叉点,散列或合并连接会更好。 但很难设计出启发式方法来捕捉这些微妙之处。
Enter the cost-based optimizer. A cost-based optimizer will enumerate possible execution plans and assign a cost to each plan, which is an estimate of the time and resources required to execute that plan. Once the possibilities have been enumerated, the optimizer picks the lowest cost plan and hands it off for execution. While a cost model is typically designed to maximize throughput (i.e. queries per second), it can be designed to favor other desirable query behavior, such as minimizing latency (i.e. time to retrieve first row) or minimizing memory usage.
输入基于成本的优化器。 基于成本的优化器将枚举可能的执行计划,并为每个计划分配一个成本,这是执行该计划所需的时间和资源的估计。 一旦列举了可能性,优化器就会选择成本最低的计划并将其交付执行。 虽然成本模型通常设计为最大化吞吐量(即每秒查询),但它可以设计为有利于其他所需的查询行为,例如最小化延迟(即检索第一行的时间)或最小化内存使用。
At this point, you may be thinking, “but what if that cost model turns out to be wrong?”. That’s a good question, and it’s true that a cost-based optimizer is only as good as the costs it assigns. Furthermore, it turns out that the accuracy of the costs are highly dependent on the accuracy of the row count estimates made by the optimizer. These are exactly what they sound like: the optimizer estimates how many rows will be returned by each stage of the query plan. This brings us to another subject of decades of research: database statistics.
此时,您可能会想,“但是如果该成本模型被证明是错误的怎么办?”。 这是一个很好的问题,而且确实基于成本的优化器的好坏取决于它分配的成本。 此外,事实证明,成本的准确性很大程度上取决于优化器所做的行计数估计的准确性。 正如它们听起来的那样:优化器估计查询计划的每个阶段将返回多少行。 这给我们带来了另一个数十年研究的主题:数据库统计。
The goal of gathering database statistics is to provide information to the optimizer so that it can make more accurate row count estimates. Useful statistics include row counts for tables, distinct and null value counts for columns, and histograms for understanding the distribution of values. This information feeds into the cost model and helps decide questions of join type, join ordering, index selection, and more.
收集数据库统计信息的目的是向优化器提供信息,以便优化器可以做出更准确的行计数估计。 有用的统计信息包括表的行计数、列的非重复值和空值计数以及用于了解值分布的直方图。 这些信息将输入到成本模型中,并帮助决定连接类型、连接顺序、索引选择等问题。
(Re)birth of an optimizer
CockroachDB started with a simple heuristic optimizer that grew more complicated over time, as optimizers tend to do. By our 2.0 release, we had started running into limitations of the heuristic design that we could not easily circumvent. Carefully-tuned heuristic rules were beginning to conflict with one another, with no clear way to decide between them. A simple heuristic like:
CockroachDB 从一个简单的启发式优化器开始,随着时间的推移,它变得越来越复杂,正如优化器往往会做的那样。 在我们的 2.0 版本中,我们已经开始遇到我们无法轻易规避的启发式设计的局限性。 精心调整的启发式规则开始相互冲突,并且没有明确的方法在它们之间做出决定。 一个简单的启发式,例如:
“use hash join when an equality condition is present”
“当存在相等条件时使用哈希连接”
became:
“use hash join when an equality condition is present, unless both inputs are sorted on the join key, in which case use a merge join”
“当存在相等条件时使用散列连接,除非两个输入都在连接键上排序,在这种情况下使用合并连接”
near the end, we contemplated heuristics like:
“use hash join when an equality condition is present, unless both inputs are sorted on the join key, in which case use a merge join; that is, except if one join input has a small number of rows and there’s an index available for the other input, in which case use a lookup join”
“当存在相等条件时使用散列连接,除非两个输入都在连接键上排序,在这种情况下使用合并连接; 也就是说,除非一个连接输入的行数较少,并且另一个输入有可用的索引,在这种情况下使用查找连接”
Every new heuristic rule we added had to be examined with respect to every heuristic rule already in place, to make sure that they played nicely with one another. And while even cost-based optimizers sometimes behave like a delicately balanced Jenga tower, heuristic optimizers fall over at much lower heights.
我们添加的每一条新的启发式规则都必须根据现有的每条启发式规则进行检查,以确保它们能够很好地配合。 尽管基于成本的优化器有时也会表现得像一座微妙平衡的 Jenga 塔,但启发式优化器却会在低得多的高度上倒塌。
By the last half of 2017, momentum was growing within Cockroach Labs to replace the heuristic optimizer that was showing its age. Peter Mattis, one of our co-founders, arranged to have an outside expert on database optimizers run a months-long bootcamp, with the goal of teaching our developers how state-of-the-art optimizers work, complete with homework assignments to read seminal papers on the subject. In order to kickstart discussion and momentum, Peter created a cost-based optimizer prototype called “opttoy”, that demonstrated some of the important concepts, and informed the production work that followed.
到 2017 年下半年,Cockroach Labs 内部取代已经过时的启发式优化器的势头不断增强。 我们的联合创始人之一 Peter Mattis 安排了一位数据库优化器方面的外部专家来举办为期数月的训练营,目的是教我们的开发人员如何最先进的优化器工作,并完成需要阅读的家庭作业 关于该主题的开创性论文。 为了启动讨论和推动势头,Peter 创建了一个名为“opttoy”的基于成本的优化器原型,它演示了一些重要概念,并为后续的生产工作提供了信息。
By the time I joined the company in early 2018, the company had come to the collective decision that it was now time to take the next step forward. Given my background and interest in the subject, I was tasked with leading a small (but highly motivated) team to build a cost-based optimizer from scratch. After 9 months of intense effort, our team is releasing the first version of the new optimizer as part of the CockroachDB 2.1 release. While there’s still much more we can (and will) do, this first release represents an important step forward. Here are a couple of important new capabilities that the 2.1 cost-based optimizer supports:
当我于 2018 年初加入公司时,公司集体决定现在是采取下一步行动的时候了。 鉴于我的背景和对该主题的兴趣,我的任务是领导一个小型(但积极性很高)团队从头开始构建基于成本的优化器。 经过 9 个月的紧张努力,我们的团队发布了新优化器的第一个版本,作为 CockroachDB 2.1 版本的一部分。 虽然我们还可以(并且将会)做更多的事情,但第一个版本代表了向前迈出的重要一步。 以下是 2.1 基于成本的优化器支持的几个重要的新功能:
Correlated subqueries 相关子查询
- these are queries that contain an inner subquery that references a column from an outer query, such as in this example:
这些查询包含引用外部查询中的列的内部子查询,例如本例中:
1
2
3
4
5
6
7SELECT *
FROM customers c
WHERE EXISTS (
SELECT *
FROM orders o
WHERE o.cust_id = c.id
)Optimizing correlated subqueries is another blog post all on its own, which I hope to cover in the future.
优化相关子查询是另一篇单独的博文,我希望将来能够介绍。
Automatic planning of lookup joins 自动规划查找连接
: When deciding how to execute a join, the optimizer now considers lookup joins, in addition to merge and hash joins. Lookup joins are important for fast execution of equality joins, where one input has a small number of rows and the other has an index on the equality condition:
在决定如何执行连接时,优化器现在除了合并和散列连接之外还考虑查找连接。 查找连接对于快速执行相等连接非常重要,其中一个输入具有少量行,另一个输入具有相等条件的索引:
1
2
3SELECT COUNT(*)
FROM customers c, orders o
WHERE c.id=o.cust_id AND c.zip='12345' AND c.name='John Doe'Here, the optimizer would consider a plan that first finds customers named “John Doe” who live in zip code “12345” (likely to be a small number of rows), and then probes into the orders table to count rows.
在这里,优化器将考虑一个计划,首先找到居住在邮政编码“12345”(可能只有少量行)的名为“John Doe”的客户,然后探测订单表以计算行数。
Under the Hood
As promised, I want to give you a quick peek under the hood of the new optimizer. To start, it’s useful to think of a query plan as a tree, with each node in the tree representing a step in the execution plan. In fact, that’s how the SQL EXPLAIN statement shows an execution plan:
正如所承诺的,我想让您快速浏览一下新优化器的幕后花絮。 首先,将查询计划视为一棵树很有用,树中的每个节点代表执行计划中的一个步骤。 事实上,这就是 SQL EXPLAIN 语句显示执行计划的方式:

This output shows how the unoptimized plan would execute: first compute a full cross-product of the customers and orders tables, then filter the resulting rows based on the
WHEREconditions, and finally compute thecount_rowsaggregate. But that would be a terrible plan! If there were 10,000 customers and 100,000 orders, then the cross-product would generate 1 billion rows, almost all of which would simply be filtered away. What a waste.此输出显示了未优化计划的执行方式:首先计算客户表和订单表的完整叉积,然后根据 WHERE 条件过滤结果行,最后计算 count_rows 聚合。 但这将是一个糟糕的计划! 如果有 10,000 个客户和 100,000 个订单,那么叉积将生成 10 亿行,几乎所有这些行都会被简单地过滤掉。 真是浪费啊。
Here’s where the optimizer proves its worth. Its job is to transform that starting plan tree into a series of logically equivalent plan trees, and then pick the tree that has the lowest cost. So what does “logically equivalent” mean? Two plan trees are logically equivalent if they both return the same data when executed (though rows can be ordered differently if there is no
ORDER BYclause). In other words, from a correctness point of view, it doesn’t matter which plan the optimizer picks; its choice is purely about maximizing performance.这就是优化器证明其价值的地方。 它的工作是将起始计划树转换为一系列逻辑上等效的计划树,然后选择成本最低的树。 那么“逻辑上等价”是什么意思呢? 如果两个计划树在执行时都返回相同的数据,那么它们在逻辑上是等效的(尽管如果没有 ORDER BY 子句,行的排序可以不同)。 换句话说,从正确性的角度来看,优化器选择哪个计划并不重要;重要的是。 它的选择纯粹是为了最大化性能。
Transformations
The optimizer does not generate the complete set of equivalent plan trees in one step. Instead, it starts with the initial tree and performs a series of incremental transformations to generate alternative trees. Each individual transformation tends to be relatively simple on its own; it is the combination of many such transformations that can solve complex optimization challenges. Watching an optimizer in action can be magical; even if you understand each individual transformation it uses, often it will find surprising combinations that yield unexpected plans. Even for the relatively simple query shown above, the optimizer applies 12 transformations to reach the final plan. Below is a diagram showing 4 of the key transformations.
优化器不会一步生成完整的一组等效计划树。 相反,它从初始树开始并执行一系列增量转换以生成替代树。 每个单独的转换本身往往相对简单; 它是许多此类转换的组合,可以解决复杂的优化挑战。 观看优化器的运行过程可能会很神奇; 即使您了解它使用的每个单独的转换,通常也会发现令人惊讶的组合,从而产生意想不到的计划。 即使对于上面显示的相对简单的查询,优化器也会应用 12 次转换来达到最终计划。 下图显示了其中 4 个关键转换。
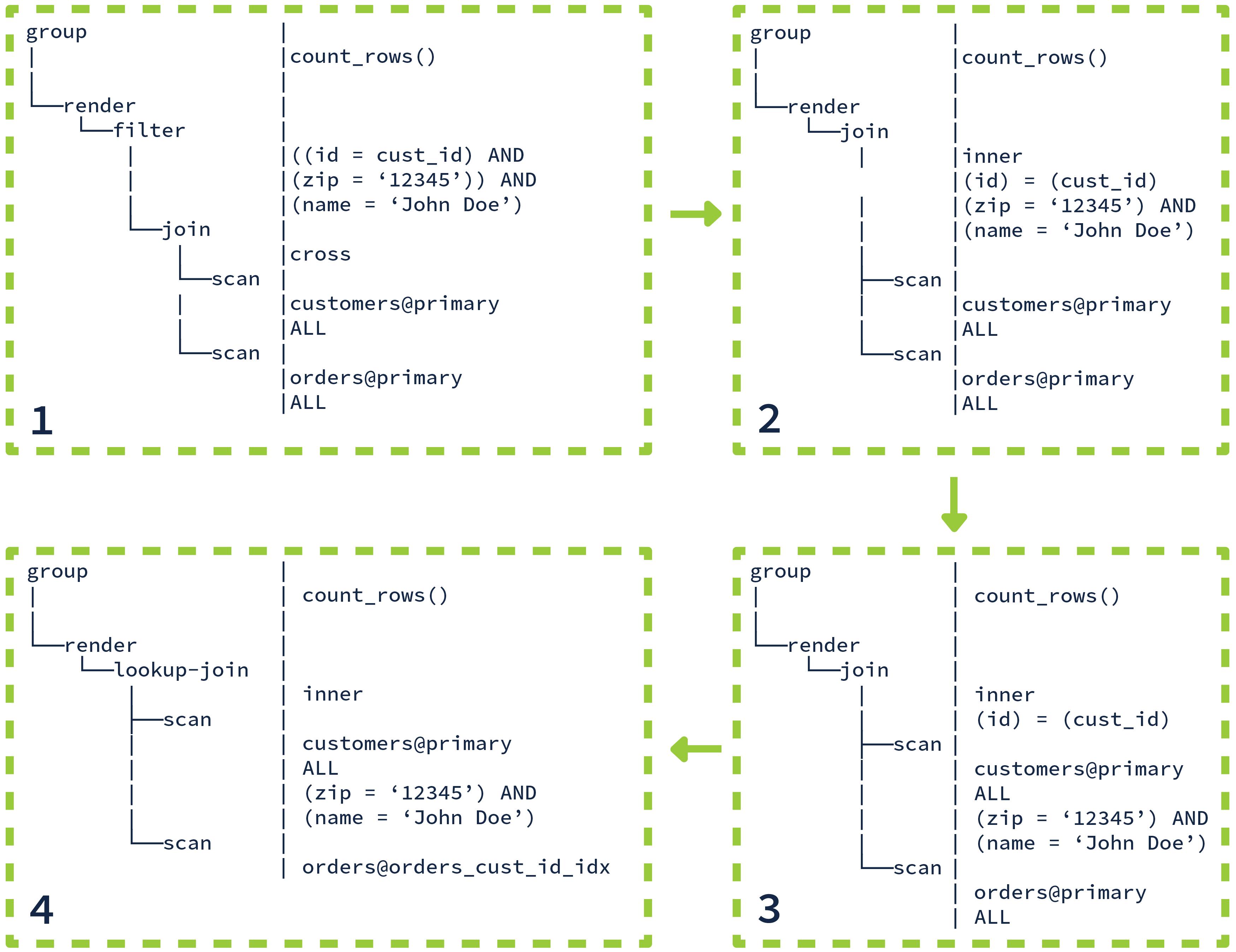
You can see that the filter conditions get “pushed down” into the join and then become part of the scan operator for maximum performance. During the final transformation, the optimizer decides to use a lookup join with a secondary index to satisfy the query.
您可以看到过滤条件被“下推”到连接中,然后成为扫描运算符的一部分以获得最大性能。 在最终转换期间,优化器决定使用具有辅助索引的查找连接来满足查询。
As of this writing, the cost-based optimizer implements over 160 different transformations, and we expect to add many more in future releases. And because transformations lie at the heart of the new optimizer, we spent a lot of time making them as easy as possible to define, understand, and maintain. To that end, we created a domain specific language (DSL) called Optgen to express the structure of transformations, along with a tool that generates production Go code from that DSL. Here is an example of a transformation expressed in the Optgen language:
截至撰写本文时,基于成本的优化器实现了 160 多种不同的转换,我们预计在未来的版本中添加更多转换。 由于转换是新优化器的核心,我们花了很多时间让它们尽可能容易定义、理解和维护。 为此,我们创建了一种名为 Optgen 的领域特定语言 (DSL) 来表达转换结构,以及一个从该 DSL 生成生产 Go 代码的工具。 以下是用 Optgen 语言表达的转换示例:
1 | [MergeSelectInnerJoin, Normalize] |
This transformation merges conditions from a WHERE clause with conditions from the ON clause of an INNER JOIN. It generates ~25 lines of Go code, including code to ensure that transitively matching transformations are applied. A future blog post will delve into more Optgen specifics, as there’s a lot there to cover. If you can’t wait for that, take a look at the documentation for Optgen. You might also take a look at some of our transformation definition files. If you’re especially ambitious, try your hand at crafting a new transformation that we’re missing; we always welcome community contributions.
此转换将 WHERE 子句中的条件与 INNER JOIN 的 ON 子句中的条件合并。 它生成约 25 行 Go 代码,包括确保应用传递匹配转换的代码。 未来的博客文章将深入探讨 Optgen 的更多细节,因为有很多内容需要介绍。 如果您等不及,请查看 Optgen 的文档。 您还可以查看我们的一些转换定义文件。 如果您特别雄心勃勃,请尝试亲手打造我们所缺少的新转型; 我们始终欢迎社区贡献。
The Memo
I’ve explained how the optimizer generates many equivalent plans and uses a cost estimate to choose from among them. That sounds good in theory, but what about the practical side of things? Doesn’t it take a potentially exponential amount of memory to store all those plans? The answer involves an ingenious data structure called a memo.
我已经解释了优化器如何生成许多等效计划并使用成本估算从其中进行选择。 这在理论上听起来不错,但实际情况又如何呢? 存储所有这些计划是否需要潜在指数级的内存量? 答案涉及一种巧妙的数据结构,称为备忘录。
A memo is designed to efficiently store a forest of plan trees for a given query by exploiting the significant redundancies across the plans. For example, a join query could have several logically equivalent plans that are identical in all ways, except that one plan uses a hash join, another uses a merge join, and the third uses a lookup join. Furthermore, each of those plans could in turn have several variants: in one variant, the left join input uses the primary index to scan rows, and in another variant it uses a secondary index to do the equivalent work. Encoded naively, the resulting exponential explosion of plans would require exponential memory to store.
备忘录旨在通过利用计划中的显着冗余来有效地存储给定查询的计划树森林。 例如,连接查询可以有多个逻辑上等效的计划,这些计划在所有方面都相同,只是一个计划使用散列连接,另一个使用合并连接,第三个使用查找连接。 此外,每个计划又可以有多种变体:在一种变体中,左连接输入使用主索引来扫描行,在另一种变体中,它使用辅助索引来完成等效的工作。 如果简单地编码,计划的指数级爆炸将需要指数级内存来存储。
The memo tackles this problem by defining a set of equivalence classes called memo groups, where each group contains a set of logically equivalent expressions. Here is an illustration:
备忘录通过定义一组称为备忘录组的等价类来解决这个问题,其中每个组包含一组逻辑上等效的表达式。 这是一个例子:
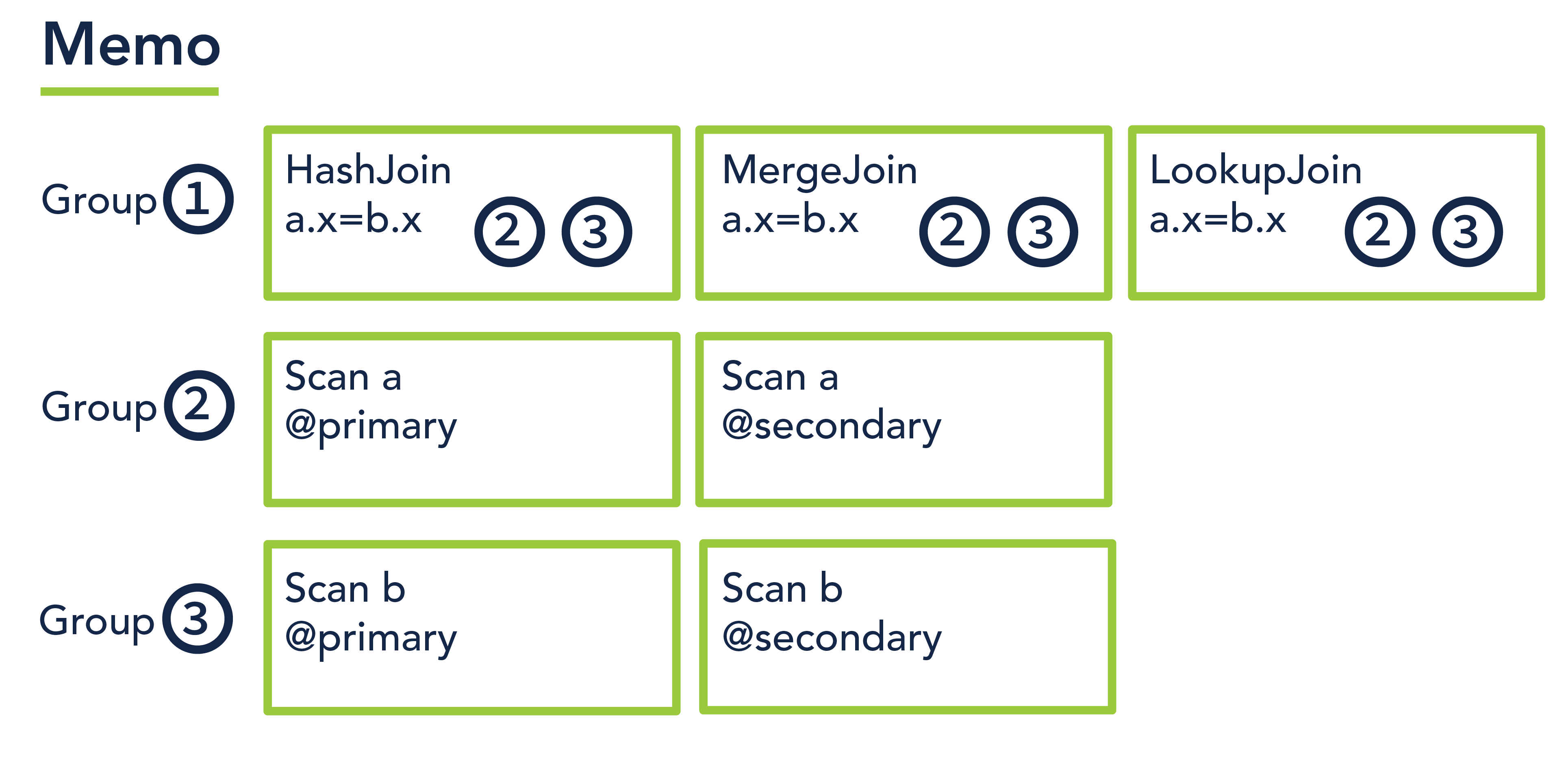
To build a plan, pick any operator from group #1, then pick its left input from group #2 and its right input from group #3. No matter which you pick, you have a legal plan, since operators in the same group are guaranteed to be logically equivalent. Simple arithmetic reveals that there are 12 possible plans (3 * 2 * 2) encoded in this memo. Now imagine a complex reporting query with a 6-way join, complex aggregation, and lots of filter conditions. The number of plans might number in the thousands, and yet would be encoded in much less space than you would expect if you weren’t aware of the memo structure.
要构建计划,请从第 1 组中选择任意运算符,然后从第 2 组中选择其左侧输入,从第 3 组中选择其右侧输入。 无论您选择哪一个,您都有一个合法的计划,因为同一组中的运算符保证在逻辑上是等效的。 简单的算术表明,这份备忘录中编码了 12 种可能的计划 (3 * 2 * 2)。 现在想象一个具有 6 路联接、复杂聚合和大量过滤条件的复杂报告查询。 计划的数量可能有数千个,但如果您不知道备忘录结构,那么编码的空间会比您预期的要少得多。
Of course the optimizer does not just randomly pick one of the possible plan trees from the memo. Instead, it tracks the lowest cost expression in each memo group, and then recursively constructs the final plan from those expressions. Indeed, the memo is a beautiful data structure, reminding me of the illuminati diamond ambigram from Dan Brown’s novel “Angels and Demons”. Both encode more information than seems possible.
当然,优化器不仅仅从备忘录中随机选择一种可能的计划树。 相反,它跟踪每个备忘录组中的最低成本表达式,然后从这些表达式递归地构造最终计划。 事实上,这份备忘录是一个漂亮的数据结构,让我想起了丹·布朗小说《天使与魔鬼》中的光明会钻石图。 两者都编码了比看起来可能更多的信息。
Conclusion
Our team plans to make future blog posts on the internals of the cost-based optimizer in CockroachDB. I’ve only scratched the surface in this post. Let us know if you’d like us to cover specific topics of interest to you. Or even better, come join Cockroach Labs, and help us build a planet-scale ACID database.
我们的团队计划在未来发表有关 CockroachDB 中基于成本的优化器内部结构的博客文章。 我在这篇文章中只触及了表面。 如果您希望我们涵盖您感兴趣的特定主题,请告诉我们。 或者更好的是,加入 Cockroach Labs,帮助我们建立一个全球规模的 ACID 数据库。
And if building a distributed SQL engine is your jam, then good news — we’re hiring! Check out our open positions here.
如果您热衷于构建分布式 SQL 引擎,那么好消息 — 我们正在招聘! 在这里查看我们的空缺职位。