Joint consensus in CockroachDB
Availability and region failure: Joint consensus in CockroachDB
At Cockroach Labs, we write quite a bit about consensus algorithms. They are a critical component of CockroachDB and we rely on them in the lower layers of our transactional, scalable, distributed key-value store. In fact, large clusters can contain tens of thousands of consensus groups because in CockroachDB, every Range (similar to a shard) is an independent consensus group. Under the hood, we run a large number of instances of Raft (a consensus algorithm), which has come with interesting engineering challenges. This post dives into one that we’ve tackled recently: adding support for atomic replication changes (“Joint Quorums”) to etcd/raft and using them in CockroachDB to improve resilience against region failures.
在 Cockroach Labs,我们写了很多关于共识算法的文章。 它们是 CockroachDB 的关键组件,我们在事务性、可扩展、分布式键值存储的较低层中依赖它们。 事实上,大型集群可以包含数万个共识组,因为在 CockroachDB 中,每个 Range(类似于分片)都是一个独立的共识组。 在幕后,我们运行了大量 Raft(一种共识算法)实例,这带来了有趣的工程挑战。 这篇文章深入探讨了我们最近解决的一个问题:向 etcd/raft 添加对原子复制更改(“联合仲裁”)的支持,并在 CockroachDB 中使用它们来提高针对区域故障的恢复能力。
A replication change is a configuration change of a Range, that is, a change in where the consistent copies of that Range should be stored. Let’s use a standard deployment topology to illustrate this.
复制更改是 Range 的配置更改,即该 Range 的一致副本的存储位置的更改。 让我们使用标准部署拓扑来说明这一点。
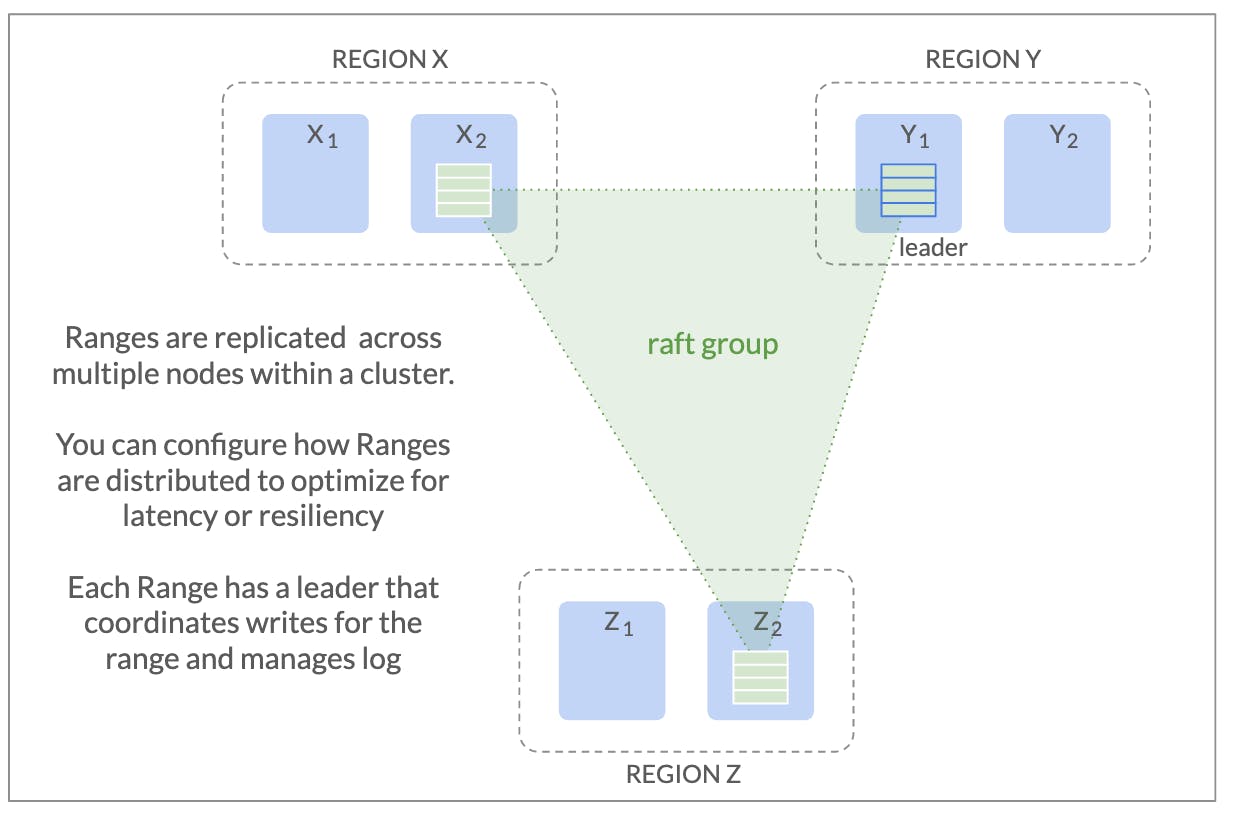
The above deployment has three regions (i.e. data centers). CockroachDB enables globally deployed applications, so these regions may well be placed across the globe. We see that there are two nodes in each of the regions X, Y and Z, and we see a Range which has one replica (“copy”) in each of the regions. This deployment survives the failure of a single region: consensus replication will continue to work as long as a majority of replicas are available. If a region fails, we lose at most one replica and two - a majority - remain, so the database will continue to operate normally after a short timeout. If we placed two replicas in, say, Z and the third replica in Y, a failure of region X would take two of the replicas with it, leaving only a single replica available; this single survivor would not be able to serve requests:
上述部署具有三个区域(即数据中心)。 CockroachDB 支持全球部署应用程序,因此这些区域很可能位于全球各地。 我们看到 X、Y 和 Z 区域中的每个区域都有两个节点,并且我们看到一个 Range,每个区域中都有一个副本(“副本”)。 此部署可以在单个区域出现故障时继续运行:只要大多数副本可用,共识复制就会继续工作。 如果一个区域发生故障,我们最多会丢失一个副本,并保留两个(大多数)副本,因此数据库将在短暂超时后继续正常运行。 如果我们在 Z 中放置两个副本,在 Y 中放置第三个副本,则区域 X 的故障将带走其中两个副本,仅留下一个副本可用; 该幸存者将无法满足请求:

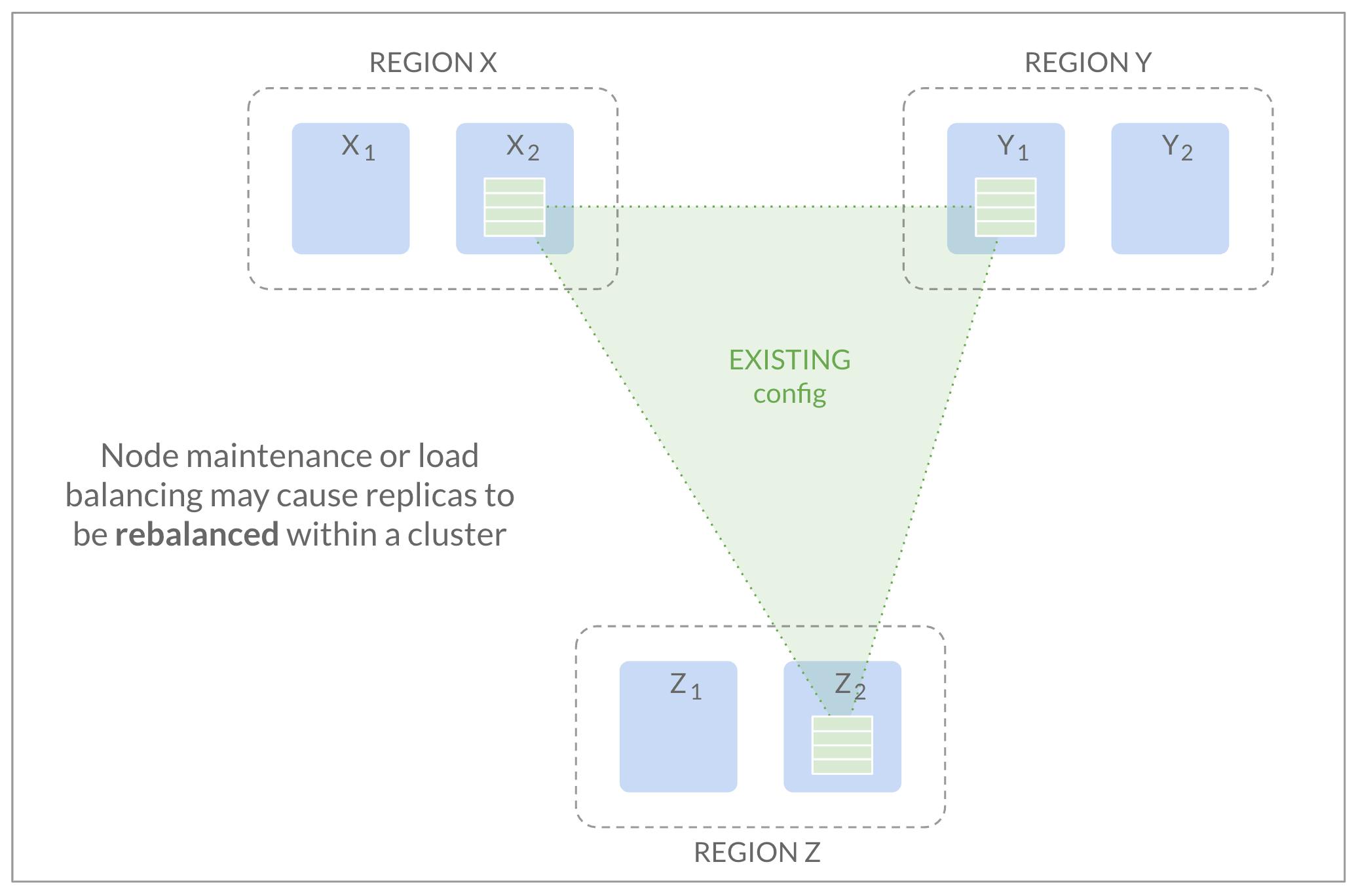
CockroachDB dynamically adjusts the data placement to account for shifts in node utilization. As a result, it may want to laterally move the replica from one node to another within, say, region X. To make it concrete, let’s say we want to move it from X2 to X1. We may want to do this because the operator has specified that X2 should go down for maintenance, or X2 has much higher CPU usage than X1.
CockroachDB 动态调整数据放置以适应节点利用率的变化。 因此,它可能希望将副本从一个节点横向移动到区域 X 内的另一个节点。为了具体起见,假设我们希望将其从 X2 移动到 X1。 我们可能想要这样做,因为操作员已指定 X2 应停机进行维护,或者 X2 的 CPU 使用率比 X1 高得多。
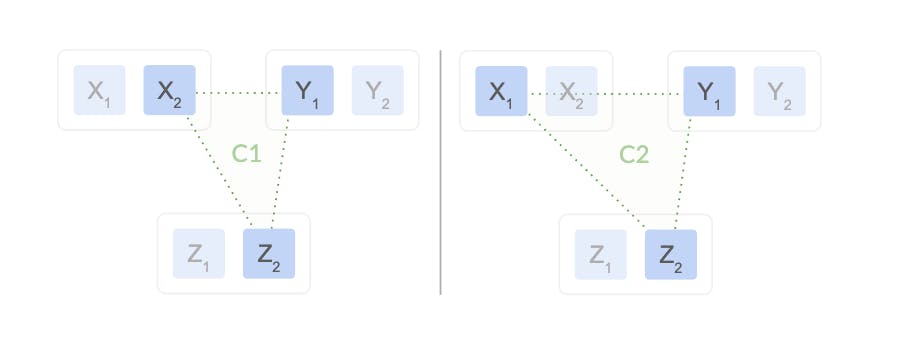
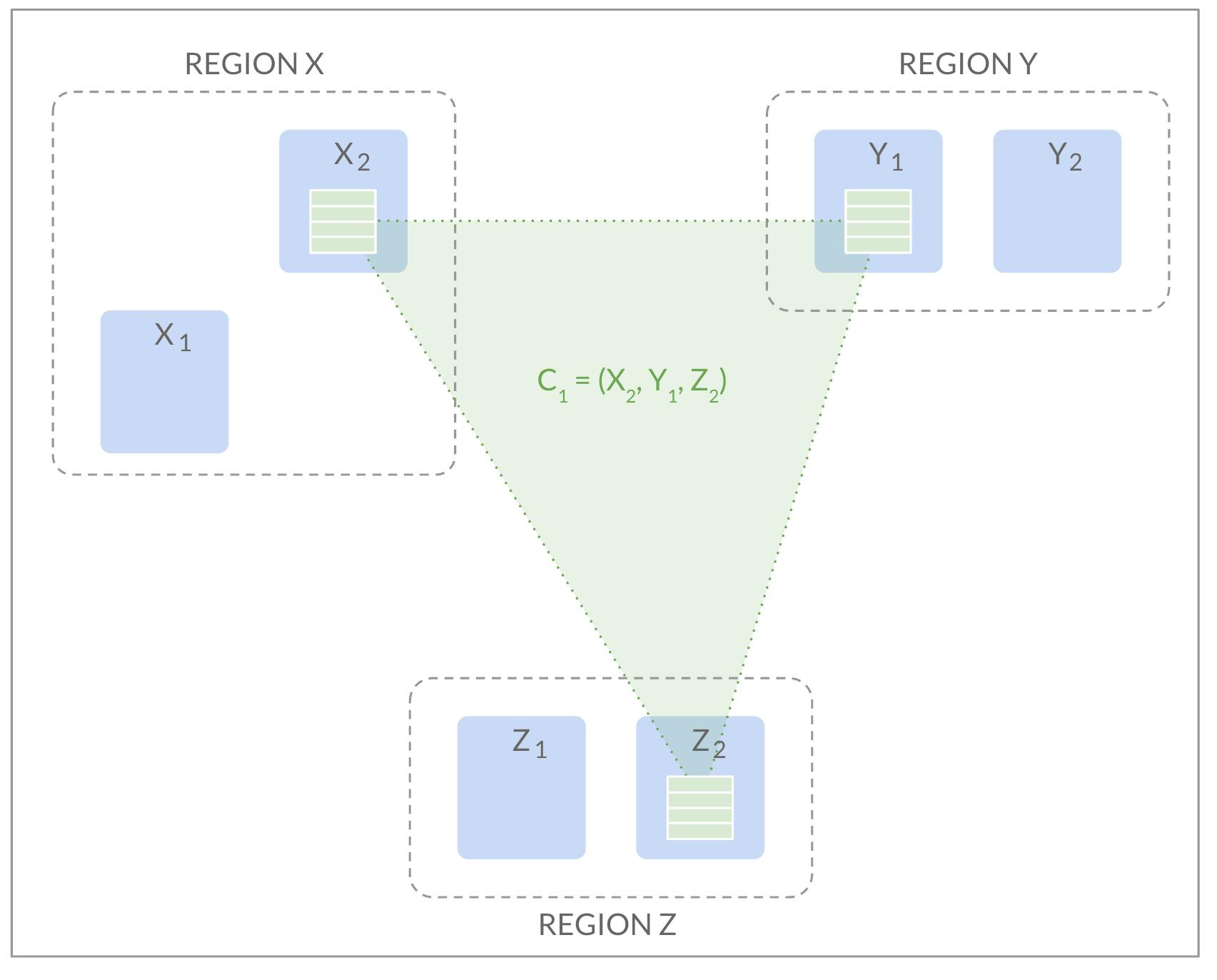
As the diagram shows, the Raft group under consideration is initially located on X2,Y1,Z2. The active configuration of this group will be the majority configuration X2,Y1,Z2, meaning two out of these three are required to make a decision (such as electing a leader, or committing a log entry).
如图所示,所考虑的 Raft 组最初位于X2、Y1、Z2 上。 该组的活动配置将是多数配置X2、Y1、Z2,这意味着需要这三个配置中的两个来做出决定(例如选举领导者或提交日志条目) )
We want to laterally move from X2 to X1, that is, we’d like to end up with replicas on X1,Y1, and Z2 in the corresponding configuration (X1,Y1,Z2). But how does that actually happen?
我们希望从 X2 横向移动到 X1,也就是说,我们希望最终在相应配置中的 X1、Y1 和 Z2 上获得副本 (* X1、Y1、Z*2)。 但这实际上是如何发生的呢?
In Raft, a configuration change is initiated by proposing a special log entry which, when received by a replica, switches it over to the new configuration. Since the replicas forming the Range receive this command at different points in time, they do not switch over in a coordinated fashion and care must be taken to avoid the dreaded “split brain” scenario, in which two distinct groups of peers both think they have the right to make decisions. Here’s how this could happen in our particular example:
在 Raft 中,配置更改是通过提出一个特殊的日志条目来启动的,当副本收到该日志条目时,会将其切换到新配置。 由于形成范围的副本在不同的时间点接收到此命令,因此它们不会以协调的方式进行切换,并且必须小心避免可怕的“裂脑”场景,在这种情况下,两个不同的对等组都认为它们拥有 做出决定的权利。 在我们的特定示例中,这是如何发生的:
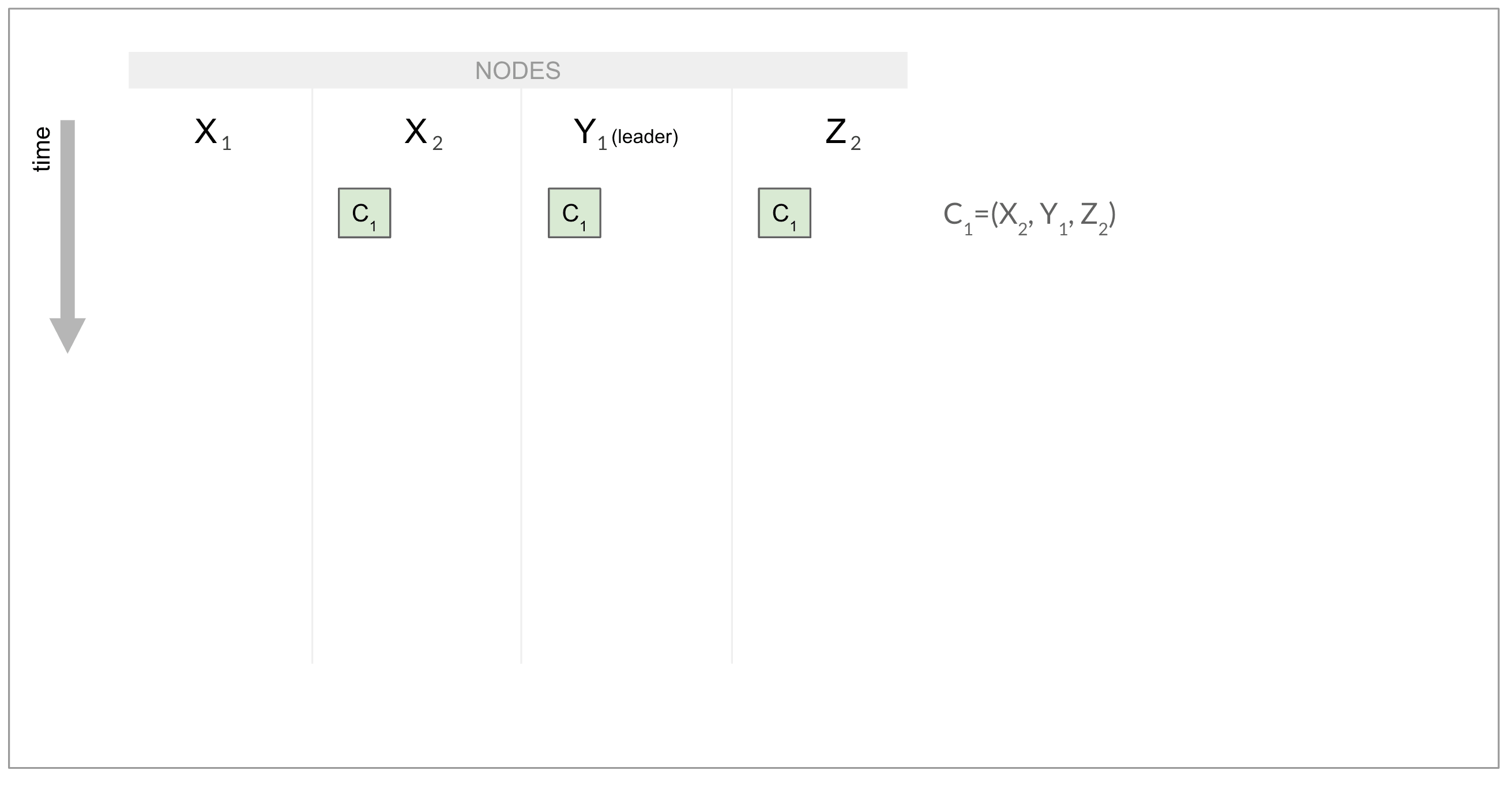
Y1 is the first node to receive the configuration change in its log, and it immediately switches to C2=X1, Y1, Z2. It catches up X1, which consequently also switches to C2. X1 and Y1 form a quorum of C2, so they can now append log entries without consulting with either X2 or Z2. But - both X2 and Z2 are still using C1=(X2, Y1, Z2) and have no idea a new configuration is active elsewhere. If they happen to not learn about this in a timely manner from Y1 - imagine a well-placed network disruption - they might decide to elect a leader between themselves and may start appending their own entries at conflicting log positions - split brain. Membership changes are tricky!
Y1 是第一个在其日志中接收配置更改的节点,它立即切换到 C2=X1, Y1, Z2。 它赶上X1,因此也切换到C2。 X1 和 Y1 形成 C2 的法定人数,因此它们现在可以附加日志条目,而无需咨询 X2 或 Z2。 但是 - X2 和 Z2 仍在使用 C1=(X2, Y1, Z2) 并且不知道新配置在其他地方处于活动状态。 如果他们碰巧没有及时从 Y1 处了解到这一点 - 想象一下适当的网络中断 - 他们可能会决定在他们之间选举一个领导者,并可能开始在冲突的日志位置附加自己的条目 - 脑裂。 会员变更很棘手!
One way to look at the above is that we were trying to “change too much at once”: we effectively added a node (X1) and removed a node (X2) at the same time. Maybe things would turn out OK if we carried these changes out individually, waiting for a majority to have received the first change before starting the second?
看待上述情况的一种方法是,我们试图“一次改变太多”:我们有效地添加了一个节点(X1)并同时删除了一个节点(X2)。 如果我们单独进行这些更改,等待大多数人收到第一个更改后再开始第二个更改,也许事情会好起来?
It turns out that this is true. Let’s add X1 first before removing X2. This means that in the above illustration we’ll have C2=(X1, X2, Y1, Z2). Note that now that there are four nodes, there are three nodes required for majority consensus. This means that when X1 and Y1 have both switched to the new configuration, they can’t make their own decisions just yet - they need to loop in one additional peer (and tell it about C2), that is, either X2 or Z2. Whichever one they pick effectively leaves a single replica using C1, but without a friend to form a separate quorum with. Similarly, we can convince ourselves that removing one node at a time is safe, too.
事实证明这是真的。 我们先添加X1,然后再删除X2。 这意味着在上图中我们将有 C2=(X1, X2, Y1, Z2)。 请注意,现在有四个节点,需要三个节点才能达成多数共识。 这意味着当 X1 和 Y1 都切换到新配置时,它们还不能做出自己的决定 - 它们需要循环一个额外的对等点(并告诉它有关 C2 的信息) ,即 X2 或 Z2。 无论他们选择哪一个,都会使用 C1 有效地留下一个副本,但没有朋友可以与之形成单独的仲裁。 同样,我们可以说服自己,一次删除一个节点也是安全的。
Breaking complex configuration changes such as lateral moves into “safer” individual parts is how CockroachDB worked for a long time. However, does it work with our deployment above? Let’s take another look at the intermediate state we’re in after adding X1, but before removing X2 (similar problems occur if we remove X2 first, then add X1):
打破复杂的配置更改(例如横向移动)到“更安全”的单独部分是 CockroachDB 长期以来的工作方式。 但是,它适用于我们上面的部署吗? 我们再看一下添加X1之后、删除X2之前的中间状态(如果我们先删除X2,然后添加X1,也会出现类似的问题):
Remember how we realized earlier that by placing two replicas in a single region, we could run into trouble? This is exactly what we were forced to do here. If region X fails, we’re in trouble: we lose two replicas at once, leaving two survivors unable to muster up the third replica required for a healthy majority (recall that a group of size four needs three replicas to make progress). As a result, this Range will stop accepting traffic until region X comes back up - violating the guarantees we were expecting from this deployment topology. We might try to argue that configuration changes are rare enough to make this a non-issue, but we’ve found that this does not hold. A CockroachDB cluster maintains many thousands of Ranges; at any given time, there might be a configuration change going on on some Range. But even without taking that into account, compromising availability in ways not transparent to the user is deeply unsatisfying to us.
还记得我们之前如何意识到,通过将两个副本放在一个区域中,我们可能会遇到麻烦吗? 这正是我们被迫在这里做的事情。 如果区域 X 发生故障,我们就会遇到麻烦:我们同时丢失两个副本,导致两个幸存者无法召集健康多数所需的第三个副本(回想一下,一个规模为 4 的小组需要三个副本才能取得进展)。 因此,该范围将停止接受流量,直到区域 X 恢复正常 - 这违反了我们对此部署拓扑的预期保证。 我们可能会试图争辩说,配置更改非常罕见,因此这不是问题,但我们发现这并不成立。 一个 CockroachDB 集群维护着数千个 Range; 在任何给定时间,某些 Range 上可能会发生配置更改。 但即使不考虑这一点,以对用户不透明的方式损害可用性也让我们非常不满意。
Until recently, CockroachDB mitigated this problem by carrying out the two adjacent membership changes as fast as possible, to minimize the time spent in the vulnerable configuration. However, it was clear that we couldn’t accept this state of affairs permanently and set out to address the issue in the 19.2 release of CockroachDB.
直到最近,CockroachDB 通过尽快执行两个相邻的成员资格更改来缓解此问题,以最大限度地减少在易受攻击的配置中花费的时间。 然而,很明显我们不能永远接受这种状况,并着手在 CockroachDB 19.2 版本中解决这个问题。
The solution to our problem is outlined in the dissertation in which the Raft consensus algorithm was first introduced, and is named Joint Consensus. The idea is to pick a better intermediate configuration than we did in our example above - one that doesn’t force us to put two replicas into a single region.
我们问题的解决方案在首次引入 Raft 共识算法的论文中概述,并被命名为“联合共识”。 我们的想法是选择一个比我们在上面的示例中更好的中间配置 - 该配置不会强迫我们将两个副本放入一个区域中。
What if our intermediate configuration instead “joined” the initial and final configuration together, requiring agreement of both? This is exactly what Joint Consensus does. Sticking to our example, we would go from our initial configuration C1=X2,Y1,Z2 to the “joint configuration” C1 && C2 = (X2,Y,Z2) && (X1,Y1,Z2):
如果我们的中间配置将初始配置和最终配置“连接”在一起,需要两者达成一致,该怎么办? 这正是联合共识所做的。 坚持我们的示例,我们将从初始配置 C1=X2,Y1,Z2 变为“联合配置”C1 && C2 = (X2 ,Y,Z2) && (X1,Y1,Z2):
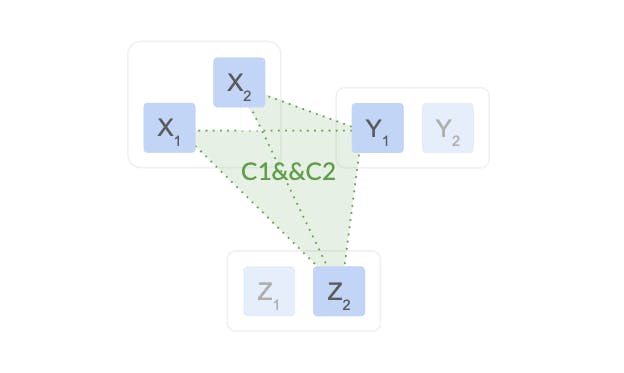
In this configuration, making a decision requires agreement of a majority of C1 as well as a majority of C2. Revisiting our earlier counter-example in which X2and Z2 had not received the old configuration yet, we find that the split-brain is impossible: X1 and Y1 (who are using the joint configuration) can’t make a decision without contacting either X2 or Z2, preventing split-brain. At the same time, the joint configuration survives a region outage just fine, since both C1 and C2 do so individually!
在此配置中,做出决定需要 C1 的多数以及 C2 的多数同意。 回顾我们之前的反例,其中X2和Z2尚未收到旧配置,我们发现裂脑是不可能的:X1和Y1(正在使用联合配置) )在不联系 X2 或 Z2 的情况下无法做出决定,从而防止脑裂。 同时,联合配置能够很好地承受区域中断,因为 C1 和 C2 都是单独执行的!
Hence, the plan was clear: implement joint configuration changes, and use them. This provided a welcome opportunity to contribute back to the community, as we share a Raft implementation with the etcd project. etcd is a distributed key-value store commonly used for configuration management (notably, it backs Kubernetes), and we’ve been an active maintainer (and user) of its etcd/raft library well before Cockroach Labs even sprung into existence in 2015.
因此,计划很明确:实施联合配置更改并使用它们。 这提供了一个回馈社区的好机会,因为我们与 etcd 项目共享 Raft 实现。 etcd 是一种常用于配置管理的分布式键值存储(值得注意的是,它支持 Kubernetes),早在 Cockroach Labs 于 2015 年出现之前,我们就一直是其 etcd/raft 库的积极维护者(和用户)。
At this point, it’s time for a juicy confession:
此时此刻,是时候进行一次多汁的坦白了:
etcd/raft doesn’t actually really implement the Raft consensus algorithm.
etcd/raft 实际上并没有真正实现 Raft 共识算法。
It does closely follow the specification for the most part, but with one marked difference: configuration changes. We’ve explained above that in Raft, a peer should switch to the new configuration the moment it is appended to its log. In etcd/raft, the peer switches to the new configuration the moment is committed and applied to the state machine.
它在很大程度上确实严格遵循规范,但有一个明显的区别:配置更改。 我们上面已经解释过,在 Raft 中,对等点应该在新配置追加到其日志时立即切换到新配置。 在 etcd/raft 中,对等方在提交并应用于状态机时切换到新配置。
The difference may seem small, but it carries weight. Briefly put,
差异看似很小,但意义重大。 简而言之,
the “Raft way” is proven correct in the paper, but more awkward use from the app, while
“Raft 方式”在论文中被证明是正确的,但在应用程序中使用起来比较尴尬,而
the “etcd/raft way” comes with subtle problems that require subtle fixes, but has a more natural external API.
“etcd/raft 方式”存在一些微妙的问题,需要微妙的修复,但具有更自然的外部 API。
We took the opportunity to discuss with the other maintainers whether etcd/raft should fall in line with the spec. In the process, we uncovered some previously unknown potential correctness problems. A little later, Peng Qu over from PingCap (they’re using a Rust implementation of Raft very similar to etcd/raft) alerted us to yet another problem.
我们借此机会与其他维护者讨论 etcd/raft 是否应该符合规范。 在此过程中,我们发现了一些以前未知的潜在正确性问题。 过了一会儿,来自 PingCap 的 Peng Qu(他们正在使用与 etcd/raft 非常相似的 Raft 的 Rust 实现)提醒我们注意另一个问题。
After we found and implemented solutions for both problems, we arrived at a good understanding about the additional invariants that truly make etcd/raft’s approach safe. At this point, neither we nor the maintainer community felt that changing to the “Raft way” now provided a good return on what would have been a very large investment in etcd/raft and all of its implementers (!). In this particular case, it seemed better to be more complicated internally, remain easy to use externally (though with a wart or two), while keeping the battle-tested code we had in place mostly intact.
在我们找到并实施这两个问题的解决方案之后,我们对真正使 etcd/raft 方法安全的额外不变量有了很好的理解。 在这一点上,我们和维护者社区都认为,改变为“Raft 方式”现在可以为 etcd/raft 及其所有实现者带来巨大的投资带来良好的回报(!)。 在这种特殊情况下,最好在内部变得更复杂,在外部保持易于使用(尽管有一两个缺点),同时保持我们现有的经过实战测试的代码基本完整。
With this detour out of the way, we went ahead and implemented joint configuration changes. Now, a few months and 22 pull requests later, anyone using etcd/raft can enjoy the well-maintained fruits of our work. Additionally, we added datadriven testing machinery that significantly simplifies testing complex interactions within Raft peers (see here for a sample). This significantly simplifies testing and provides fertile grounds for future work or even just explorations.
绕过这个弯路后,我们继续实施联合配置更改。 现在,几个月和 22 个 Pull 请求之后,任何使用 etcd/raft 的人都可以享受我们维护良好的工作成果。 此外,我们添加了数据驱动的测试机制,显着简化了 Raft 对等体中复杂交互的测试(请参阅此处的示例)。 这极大地简化了测试,并为未来的工作甚至探索提供了肥沃的基础。
Naturally we also started using this new functionality in CockroachDB’s recent 19.2 release. If you haven’t given us a try yet, it’s easy to do so either locally or in the cloud.
当然,我们也在 CockroachDB 最近的 19.2 版本中开始使用这个新功能。 如果您还没有尝试过,可以在本地或云端轻松尝试。